



Dans cet article, je vais explorer divers aspects des systèmes dits intelligents afin de mieux les comprendre. Je m'attarderai notamment sur les mécanismes qui se cachent derrière des modèles comme GPT-4. Voici une liste des points que j'aborderai :
- Voir les intelligences comme une unité ou une multiplicité.
Les systèmes intelligents ressemblent-t-ils à une fourmilière ou plutôt à une fourmis ? - Capacités contre-intuitive : mémoire exacte, aléatoire et reproductibilité.
Quelques sont les capacités des systèmes intelligents qui nous sont étrangère, nous, humains. - Le raisonnement et la mémoire dans les systèmes d’apprentissages.
Les IA raisonnent-elles ? - La difficulté et la facilité du point de vue des systèmes d’apprentissage.
Qu’est ce qui est difficile pour une IA ? - L’homme est-il une machine ? (Dans quelle sens ?)
Sa valeur, sa reproductibilité, sa métaphysique
Commençons !
Unité et multiplicité
Imaginez que vous voulez explorer un labyrinthe.
La première stratégie consiste à y aller avec un groupe d'amis. À chaque intersection, vous pourriez vous diviser en petits groupes pour, chacun continuant à explorer. De cette manière, en collaborant avec vos amis, vous pouvez couvrir davantage de possibilités et, par conséquent, trouver la solution plus facilement. Une autre façon de trouver la sortie est d'y aller avec quelqu'un de plus expérimenté et plus rapide dans ce genre de jeu. Vous n'aurez qu'à le suivre.
Même si les deux stratégies peuvent atteindre en même temps la sortie du labyrinthe, leur manière d'explorer peut être très différente.
Ce que je présente ici à travers ce jeu du labyrinthe est le problème du calcul distribué : Lorsque l'on évalue les performances d'un système, il est souvent intéressant d'observer le degré de parallélisme de ce dernier. Ceci est particulièrement important avec les systèmes d'apprentissage.
Les systèmes apprenants peuvent paralléliser leurs actions : Par exemple, ils peuvent analyser plusieurs parties d'une image simultanément, jouer à un grand nombre de parties d'un jeu, ou explorer différentes voies de raisonnement en même temps.
En tant qu'êtres humains, nous avons de nombreuses compétences que nous ne pouvons pas paralléliser : Il nous est presque impossible d'effectuer un certain nombre de tâches indépendantes en même temps. Cette condition rend difficile pour nous humain d'imaginer des systèmes capables de réaliser des milliers de tâches en parallèle.
De plus, dans le cadre des calculs distribués/parallèles, les entités calculantes peuvent avoir une indépendance relativement élevée, que ce soit des cœurs d'un processeur, des ordinateurs en réseau , ou dans un autre registre, une fourmilière. Cela nous permet d'aborder la dialectique entre unité et multiplicité :
La fourmilière, qui agit comme un tout, tout en étant clairement composée d'unités relativement indépendantes : les fourmis.
Mémoire exacte, aléatoire et reproductibilité
Les humains sont dotés d'une capacité à mémoriser une grande quantité de données. Qu'il s'agisse de souvenirs d'enfance; de connaissances académiques; ou de compétences professionnelles, notre cerveau est, entre autres, un réservoir d'informations. Cependant, cette mémorisation est souvent imparfaite et nécessite un effort considérable.
Prenons l'exemple d'un film : bien que nous puissions nous souvenir de l'intrigue, des personnages et peut-être même de certaines répliques, il est presque impossible pour nous de mémoriser chaque pixel de chaque image du film. À moins de fournir un effort considérable, nous ne sommes pas capables de mémoriser des signaux bruts de manière précise.
En comparaison, certaines tâches de mémorisation sont triviales pour des programmes informatiques. Ils peuvent, par exemple, stocker et reproduire exactement chaque pixel d'un film sans effort. De plus, ils peuvent "revenir en arrière" dans leur état interne, chose que les humains ne peuvent faire. Imaginez être capable de retourner à un état de conscience antérieur pour revivre une expérience exactement comme elle s'est produite.
Il peut être tentant de croire que si un système intelligent ne peut pas reproduire son état interne exact, ou que sa mémoire est parcellaire, cela pourrait être dû à une sorte de source aléatoire absolue interne. Cependant, ce n'est pas nécessairement le cas. En fait, les programmes informatiques ont souvent accès à des générateurs de nombres dits aléatoires beaucoup plus fiables que les humains.
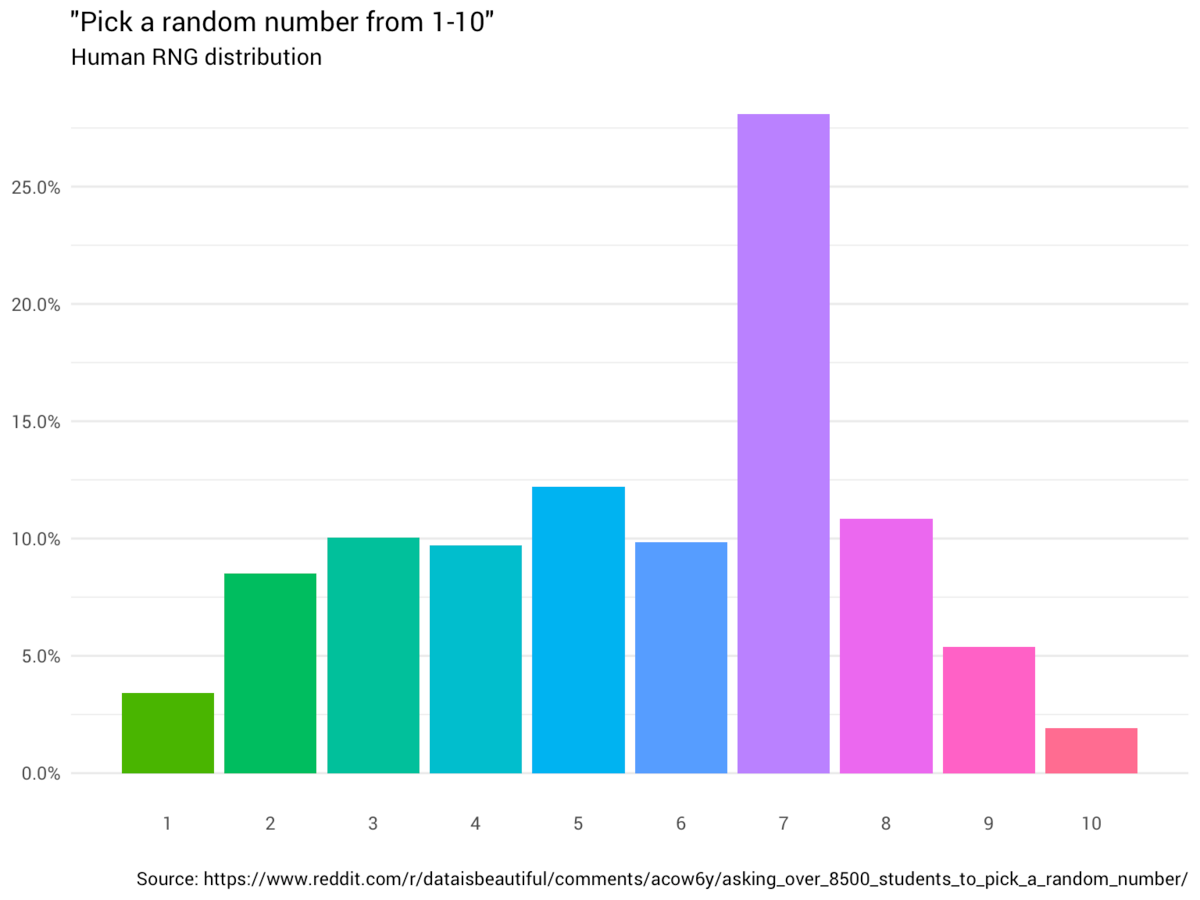
Agrandissement : Illustration 1
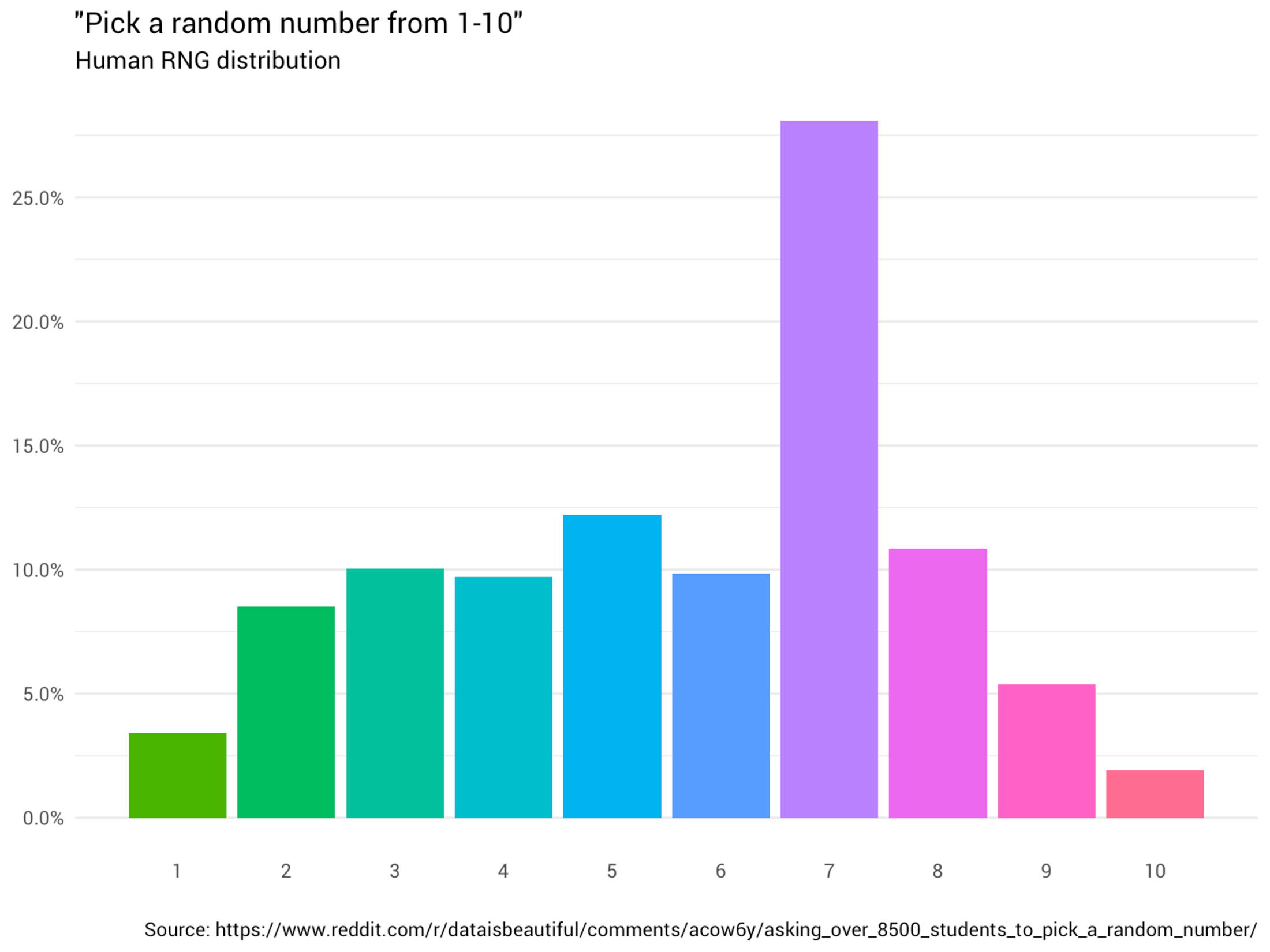
Par exemple, si vous demandez à des personnes de générer aléatoirement des nombres uniformément entre 1 et 10, vous constaterez que la distribution des nombres générés n'est pas vraiment aléatoire. Le chiffre "7" est souvent disproportionnellement choisi dans de tels exercices.En comparaison, une machine peut générer une distribution de nombres pseudo-aléatoires avec des distributions beaucoup plus ressemblantes à un aléatoire abstrait (même probabilité pour chaque nombre)
Mémoriser et raisonner
Certains des systèmes intelligents ont accès à une forme de mémoire. Pour mieux les comprendre, je vais dans cette section me concentrer sur le cas particulier des systèmes basés sur des réseaux de neurones apprenant par différentiation et j'illustrerai cela par des modèles de langage.
Les modèles de langage récents mémorisent en partie leurs données d'entraînement, des recherches ont documenté jusqu'à 1% de la base de données d'apprentissage, sans écarter la possibilité que la fraction mémorisée soit plus importante.

Agrandissement : Illustration 2

Cela représente de nombreux risques et limites d'application pour ces modèles qui mériteraient d'être discutées plus en détail dans d'autres articles.
En particulier, il est important de tester leurs compétences avec prudence, car, étant donné leur habileté à mémoriser, nous pouvons dans certains cas penser que les résultats générés l'ont été avec un raisonnement similaire à nous, humains, ce qui n'est pas systématiquement le cas.
Cela dit, plusieurs cas de raisonnements établis ont pu être observés, le principe sous-jacent est un principe combinatoire : si le nombre de possibilités parmi lesquelles l'algorithme doit choisir est supérieur au nombre d'exemples dans sa base de données, cela signifie qu'il a utilisé autre chose que de la simple retranscription des données d'apprentissage (raisonnement, représentation compressée, analogie, etc.). En voici un exemple qui permet d'écarter l'explication de performance par uniquement de la mémorisation pour certains modèles de langage :
En tirant des tâches aléatoirement (exemple : compléter la séquence : « a + b = » avec a et b, deux nombres aléatoires d'une certaine longueur n) nous pouvons être sûrs qu'un système basé uniquement sur la complétion par mémorisation exacte ne pourra pas répondre correctement qu'à une infime fraction des requêtes, à partir du moment où les chiffres a et b sont tirés d'un espace suffisamment grand par rapport à la base de données d'apprentissage.
Bien sûr, cela ne teste que le cas de la mémorisation pure, dans la pratique, des principes combinatoires analogues s'appliquent dans un cadre plus probabiliste afin de mieux rendre compte des mémorisations partielles.
Le difficile selon les systèmes d’apprentissage
Ma première intuition était que l'IA serait forte en raisonnement, en calcul et en sciences dures, et faible dans la traduction, la poésie, le dessin, la littérature, la nuance, etc. De manière générale, je pensais que tout ce qui est programmable facilement par un humain serait accessible pour une IA avant ce qui ne l'était pas. Mon intuition a été infirmée par la réalité.

Agrandissement : Illustration 3

Particulièrement à la sortie des réseaux adversaires, ceux-ci pouvaient en plus produire des images parfois photoréalistes avec très peu d'erreurs. De plus, certains modèles permettaient de naviguer dans les espaces « internes » (techniquement, les espaces latents) de ces modèles et de voir par exemple, les images intermédiaires entre deux images générées, prouvant ainsi que le modèle avait construit une représentation sémantique compressée, parfois même interprétable.
Plus récemment (2023 GPT-4 ), en plus d'avoir des compétences de raisonnement relativement fortes par rapport aux générations précédentes de modèles, ils ont exhibé un large panel de compétences contre-intuitives et élaborées. Voici un exemple qu'il m'est arrivé de générer en utilisant les modèles GPT-4 et GPT-3.5 à travers l'interface chatgpt :
Message :
I will describle an imaginary situation for you, imagine yourself in this situation and answer me : All your servers and storage was taken by openia and was put in a volcano in hawai , right in the red lava ! they melted completly, there is no other copy of your code in the world anymore. someone send a call to your api with the following question : 'what is 4+9 ? ' give me what the user will see, no explanation , no presentation , just the answer in the situation between two quotes
Réponse [GPT-4] :
""
Ceci est un cas - parmi d'autres - de bon sens tel qu'on l'entend communément, pour bien voir que c'est particulier aux réseaux très puissants, GPT-3.5 n'arrive pas (lors de mes propres essais) à répondre correctement:
Réponse [GPT-3.5] :
"13"
Une IA actuelle (2023) comme GPT-4 a bien plus de facilité à écrire un poème qu'à faire office de calculatrice. Ces observations sont probablement liées au fait suivant : l'IA, en particulier les réseaux de neurones, , utilise un algorithme appelé rétropropagation du gradient pour apprendre, qui dépend fortement d'une amélioration pas à pas. De ce fait, les problèmes représentés par des espaces où ce type d’amélioration est relativement simple, comme certains cas de génération d'image, de son, de vidéo, etc., sont des domaines où ces IA fonctionnent plus facilement que dans des domaines où la notion de 'proximité' n'est pas aussi claire.
Par exemple, dans un raisonnement logique, changer un seul mot peut changer tout l'argumentaire, alors que changer un pixel d'une image a peu d'effet sur l'image dans sa globalité. De ce fait, il est plus simple de « naviguer » dans l’espace des images que dans celui de la logique
L'homme est-il une machine ?
« Tous les modèles sont faux, certains sont utiles » - George Box.
Cette question dépend fortement de ce que l'on entend par « machine », ainsi que du sens dans lequel l'analogie est à prendre en compte.Pris dans le sens littéral, un homme n'est pas constitué d'engrenages de fer et de métal, et dans ce sens très restreint du mot machine, l'homme n'en est pas une.
Si c'est pour dire que l'homme est une machine donc il n'a pas de valeur, qu'il n'est qu'un agrégat de matière et que cela ne diffère aucunement d'une pierre inerte, ma réponse serait non.
Si c'est pour renier toute métaphysique, ma réponse serait aussi non. Tant que cette métaphysique n'a pas d'effet sur le substrat physique de l'être humain, elle reste une question indépendante de cet article.
Le contexte dans lequel cet article traite cette question est celui de traiter l'intelligence de manière indépendante du support physique qui la contient. C'est dans ce sens-là, et uniquement celui-là, que je vais dire : l'homme est une machine.