



Les réseaux sociaux joueront un rôle crucial dans la campagne pour les élections européennes, à la fois comme source d’information et comme arène du débat public.
Dans cette édition, nous reviendrons à plusieurs reprises sur les difficultés, les biais, les limites que rencontre, à l’heure actuelle, la discussion politique sur les réseaux sociaux. Il s’agit de difficultés d’ordre social, communicatif, sémiologique, sociolinguistique et psycholinguistique qui demandent des actions importantes de sensibilisation et éducation pour que les citoyens puissent se servir de ces outils en tirant pleinement profit de leur potentiel.
Dans ce billet nous nous focaliserons sur l’effet de ségrégation induit par l’utilisation des plateformes numériques comme lieu d’information et de discussion politique.
Depuis l’étude d’Eli Pariser sur les bulles de filtrage, nous sommes conscients du fait que Facebook, Twitter, Youtube et les autres plateformes numériques commerciales n’ont pas été conçues avec l’objectif de nous informer, mais plutôt avec l’objectif de capturer notre attention pour nous retenir en ligne et pour nous exposer à des contenus publicitaires susceptibles de nous intéresser. Pour capturer notre attention, ces plateformes nous exposent à des contenus adaptés à notre profil. Ces contenus sont déterminés par de complexes processus algorithmiques, appelés « algorithmes de personnalisation », capables de prendre des décisions complètement automatisées à propos des contenus à privilégier ou à pénaliser pour chaque usager. L’utilisation de ces algorithmes par les plateformes numériques produit l’effet de ségréguer chaque usager dans une « bulle de filtrage » dans laquelle il ne fera qu’être exposé à des contenus qui confirmeront son opinion et sa vision du monde. Qui plus est, ces algorithmes restent secrets.
Claudio Agosti, Umberto Boschi, Stefania Milan et Federico Sarchi travaillent au projet ALEX (ALgorithms Exposed. Investigating Automated Personalization and Filtering for Research and Activism), qui vise à dévoiler le fonctionnement des algorithmes de personnalisation sur les réseaux sociaux, en analysant d’abord Facebook et Youtube à titre de test.
Le projet ALEX démarrera à l’occasion des élections européennes avec une expérience conduite à l’échelle continentale dont les motivations et la mise en place sont décrites dans deux articles (ici et là) que nos collègues nous ont gentiment autorisés à synthétiser et traduire (2) pour cette édition.
Nous leur donnons la parole.
-----
Après que la sonnette d’alarme ait été tirée lorsque le scandale de Cambridge Analytica est sorti dans les médias internationaux, la commissaire européenne pour la Justice, Věra Jourová, parlait d’un « signe clair d’avertissement » que les élections européennes à venir pourraient souffrir de la même « désinformation et manipulation par des intérêts privés et étranger » qui avait affecté les élections américaines.
Une grande partie du succès de cette vague déferlante de la droite populiste serait due au résultat de leur campagne sur les réseaux sociaux. L’algorithme de Facebook évoqué est en fait capable de déterminer le succès ou l’échec d’une campagne spécifique, divisant les candidats entre ceux qui savent mettre à profit ce procédé et ceux qui l’ignorent. Au-delà de la face émergée de l’iceberg, on peut s’attendre à ce que les mécanismes de l’algorithme continuent d’augmenter la polarisation des opinions.
Eli Pariser, l’auteur de The Filter Bubble, donne un exemple clair du fonctionnement de cette polarisation : deux de ses amis ont recherché « BP » sur Google. « L’un d’entre eux a trouvé un certain nombre de liens sur les opportunités d’investir dans le British Petroleum. L’autre a reçu des informations sur le déversement d’hydrocarbures. » On doit prendre connaissance du fait que les algorithmes influencent de manière significative notre perception du monde et, par conséquent, tout le processus de la prise de décision d’un individu. Souvent, ils empêchent chaque individu de voir non seulement le spectre complet des différentes opinions, mais aussi le spectre complet des faits.
Même les priorités et les sujets d’une campagne électorale en sont affectés : dans le passé, ils étaient souvent établis par les camps en compétition ou par les préférences de l’opinion publique. Aujourd’hui, en revanche, ce sont les algorithmes eux-mêmes qui définissent les thèmes et les priorités des campagnes en nous montrant seulement ce qu’ils considèrent intéressant pour nous et en cachant ce qu’ils calculent comme moins important.
Comme montré par l’analyse de la Web Foundation, « Facebook semble définir les informations des utilisateurs en se basant sur des critères qui ne sont pas visibles à ces mêmes utilisateurs ». Les utilisateurs des réseaux sociaux – incluant les chercheurs et les journalistes – peuvent penser qu’ils sont « désintermédiés » quand ils accèdent à l’information, mais ils n’ont pas les moyens de comprendre comment le contenu ou les informations qu’ils reçoivent ont été produits.
Si Facebook a promis plus de transparence, c’était seulement en réponse à une requête des institutions, mais il ne l’a jamais fait d’une manière proactive. Le meilleur résultat des derniers efforts de Facebook pour faire preuve de transparence est l’aboutissement de l’API (i.e. un flux de données lisible à la machine). Cela peut être utilisé par les chercheurs pour acquérir des données sur les publicités électorales. Mais il reste à Facebook de décider ce qui peut être considéré comme politiquement pertinent ou non, étant donné que les chercheurs doivent signer un accord de non divulgation et qu’il n’est pas prévu une quelconque forme de contrôle de la part d’un tiers.
L’un des principes de base du Règlement Général sur la Protection des Données européennes (RGPD) est le contrôle sur les données propres à chacun. Mais pour sortir de sa propre bulle de filtrage, le meilleur moyen serait d’acquérir un contrôle total sur son propre algorithme, sur son propre flux d’informations.
La question est « Comment » ?
Le projet ALEX, Algorithms Exposed, financé par une bourse Proof of Concept du Conseil européen de la recherche, intervient dans ce cadre en promouvant une approche du contrôle des algorithmes qui puisse en même temps sensibiliser et donner pouvoir aux utilisateurs. ALEX stabilise et élargit les fonctionnalités d’une extension de navigateur, fbtrex, une idée originelle du chef développeur Claudio Agosti. À travers l’analyse des sorties de l’algorithme du fil d’actualité de Facebook, notre logiciel permet aux utilisateurs de surveiller l’usage qu’ils font des réseaux sociaux et d’offrir, le cas échéant, leurs données de façon volontaire pour des projets scientifiques ou bénévoles de leur choix. Il habilite aussi les utilisateurs avancés, tels que les chercheurs et les journalistes, à produire des études sophistiquées des biais introduits par les algorithmes. En prenant Facebook et les élections européennes à venir comme cas d’étude, ALEX dévoile le fonctionnement des algorithmes de personnalisation sur les réseaux sociaux.
Nous proposons cette expérience sur la base de quelques acquis précédents que nous allons décrire de suite.
En décembre 2018, le quotidien The Guardian a publié un reportage intitulé Comment les populistes italiens ont utilisé Facebook pour gagner les élections’ En exploitant les données du MediaLab de l’Université de Pise, les auteurs du reportage ont montré comment les deux chefs de file, à savoir Matteo Salvini (Ligue) et Luigi di Maio (Mouvement Cinq Etoiles), ont réussi à contourner la couverture de la presse et des médias grand public : pendant les deux mois de campagne électorale, tout en atteignant ensemble sur Facebook 7,8 millions de « j’aime » et de partages. La plupart du contenu consistait dans des vidéos virales et dans la diffusion en direct de messages improvisés et/ou privés, qui touchent les utilisateurs dans l’espace intime de leur page Facebook personnelle.
L’analyse publiée par The Guardian était basée sur la mesure du taux d’engagement des utilisateurs par rapport aux contenus proposés par les candidats. Même si cela peut aider dans la description du résultat politique, selon nous, cela ne donne pas un cadre complet. En effet, le taux d’engagement des utilisateurs est une mesure produite par un mélange de trois facteurs différents.
Le premier facteur est lié à la quantité de contenus produits par une page (ou un candidat). Souvent, des candidats comme Matteo Salvini, qui peuvent compter sur une stratégie de communication et sur une équipe gérant leurs comptes sur les réseaux sociaux, produisent plus de contenus qu’un seul individu le pourrait normalement.
Le deuxième facteur concerne les algorithmes de priorité de Facebook, qui pour des raisons inconnues préfèrent un certain contenu par rapport à d’autres, le proposent constamment à une personne et inversement le cachent à d’autres utilisateurs. Le fonctionnement de cet algorithme n’est pas clair, mais nous avons de bonnes raisons de croire qu’il a un fort impact sur les résultats.
Le troisième facteur est lié à la mesure de l’engagement en soi, à savoir ce que l’on peut observer par rapport à l’interaction d’une certaine portion de l’électorat avec son candidat préféré.
Ces facteurs ont des implications politiques distinctes – respectivement, le rôle d’un candidat, l’intervention des algorithmes opaques, et les intérêts politiques légitimes de l’électorat – et ne peuvent pas être uniquement réduits à des indicateurs de l’engagement des utilisateurs.
Nous avons également mené, à l’époque des élections législatives italiennes une étude (mars 2018), en utilisant fbtrex et des bots conçus ad hoc pour recueillir les preuves de la manipulation algorithmique sur les réseaux sociaux.
Comment avons-nous procédé ?
Nous avons sélectionné 30 pages Facebook de toutes orientations politiques, en identifiant les six pages les plus actives pour cinq orientations politiques différentes. Nous avons enregistrés les contenus de ces pages à l’aide d’une Facebook API qui n’est plus disponible à l’heure qu’il est. Cela nous a permis de recueillir les posts sélectionnées par Facebook comme preuve de la sélection algorithmique opérée. Parallèlement, nous avons créé six profils (nos « bots »). Les six bots suivaient tous les 30 pages, ils effectuaient un défilement vers le bas dans les fils d’actualités Facebook au même temps, 13 fois par jour, mais ils distribuaient des « j’aime » de façon variable en fonction de différentes orientations politiques. Nous avons ainsi pu simuler six profils intéressés par les mêmes contenus mais ayant des orientations politiques différentes.
Tous les affichages publics sur le « mur » de ces six profils ont été collectés de sorte à montrer aux usagers ce que Facebook sélectionne à partir des profils de chaque utilisateur. En comparant les données provenant de différents profils, nous avons eu un aperçu de la sélection algorithmique. Nous avons ensuite produit des métriques adaptés à comparer le type de contenu et la répétition des posts, par rapport aux contenus d’origine. Dans un milieu contrôlé, nous avons identifié des tendances émergentes parmi les fils d’actualités Facebook de nos profils.
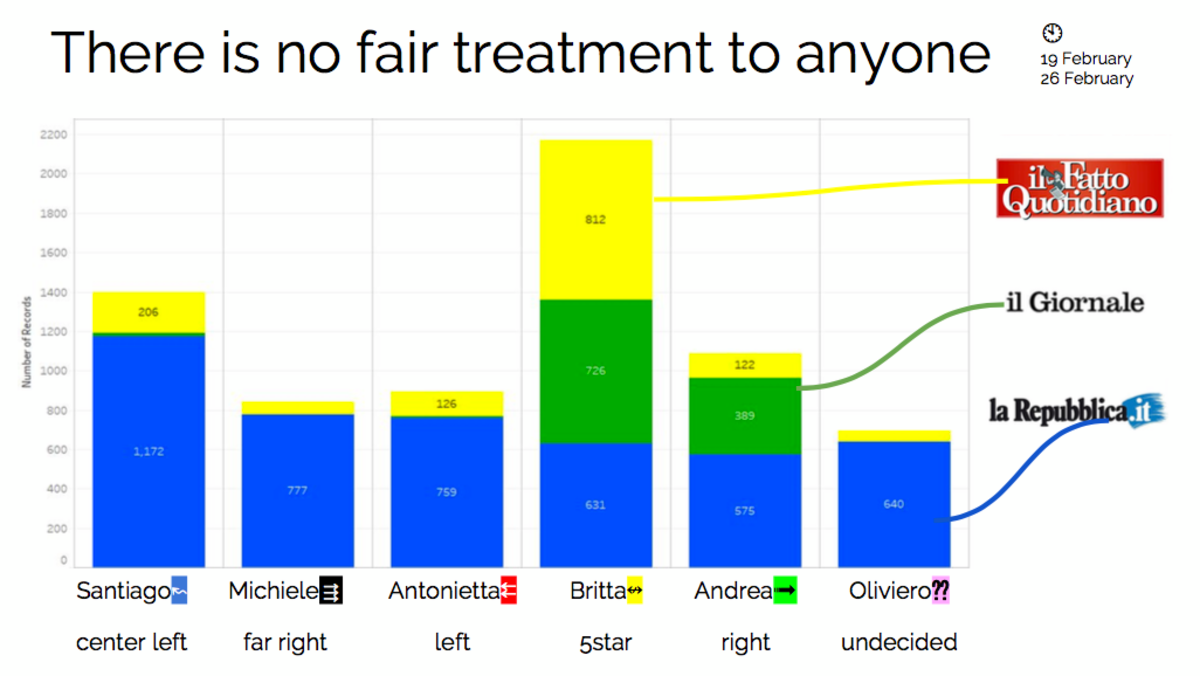
Agrandissement : Illustration 1
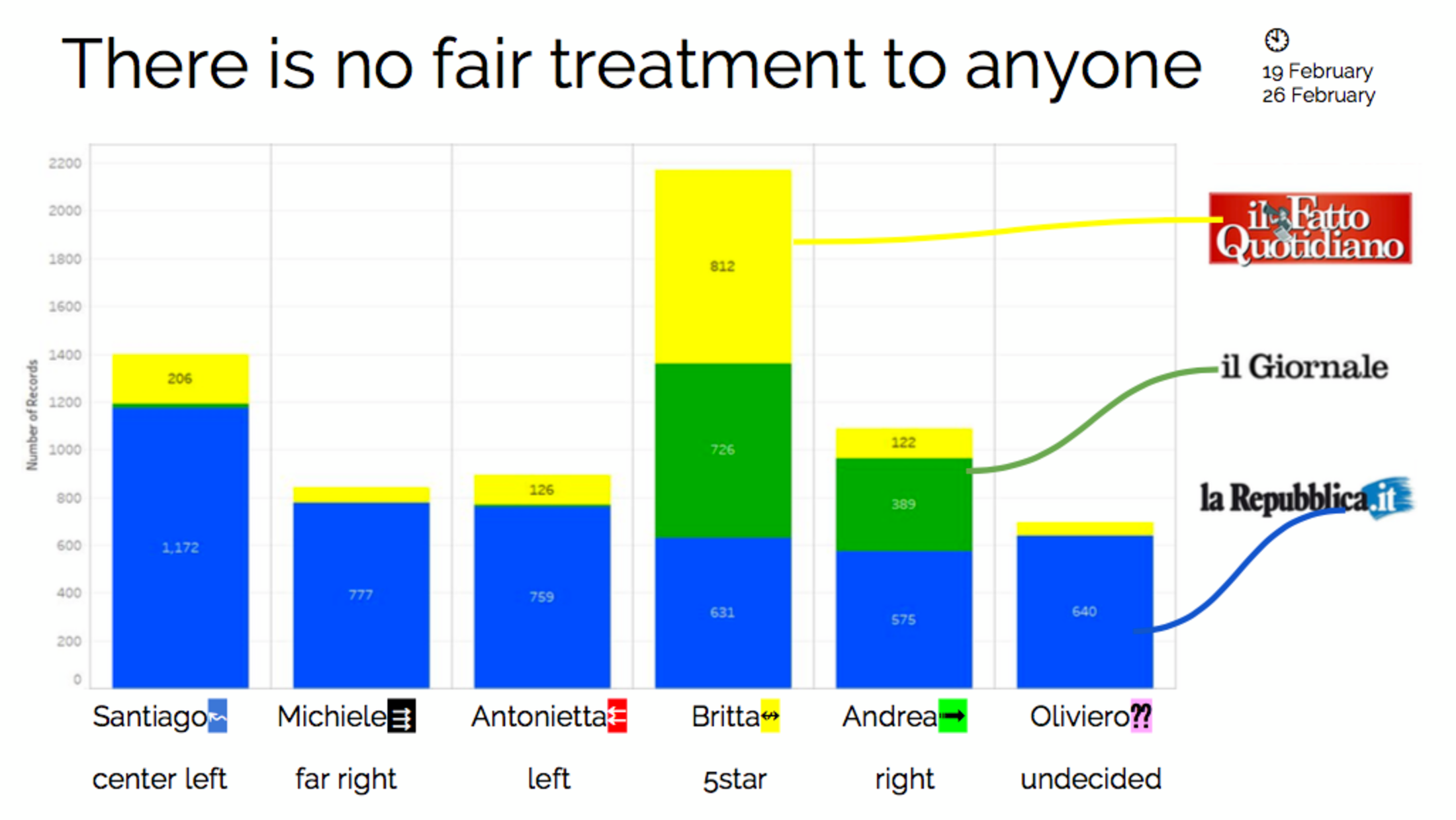
Par exemple, le pourcentage de variété de contenus auxquels les profils ont été exposés s’est avéré stable et prévisible pour tous les profils : chaque usager obtient une seule et même valeur proportionnelle récurrente. L’individu avec plus de photographies que de textes par exemple, continue à être exposé à plus de photographies. Quant au pourcentage des posts qui ont été affichés plus d’une fois dans un fil d’actualités donné, cela varie selon les profils. Et ce pourcentage semble être influencé par la « variété informationnelle » à laquelle un profil est exposé. Pour un compte rendu plus détaillé, veuillez regarder l’intervention de Claudio Agosti dans le cadre de Chaos Computer Conference 2018. Les slides sont à votre disposition en cliquant ici.
L’expérience conduite pendant les élections italiennes montre qu’en période d’élections plus particulièrement, il est extrêmement important d’armer les usagers pour qu’ils puissent se libérer de leurs bulles de filtrage. Or, la revendication de la propre souveraineté algorithmique, autrement dit, la récupération de la maîtrise totale de ses cyberactivités pour lutter contre les algorithmes de personnalisation, n’est pas une tâche facile. Ici nous proposons des éléments, qui devraient être intégrées aux projets à tout projet à venir qui comme fbtrex visera à établir une souveraineté algorithmique.
- Premièrement, les efforts de contrôle des algorithmes devraient se propager en dehors du monde des experts – notamment la communauté académique et industrielle – pour y inclure les usagers. L’autodétermination devrait être un engagement au niveau communautaire si nous voulons agir contre l’hégémonie algorithmique actuelle, monopolisée par un petit nombre de géants du numérique.
- L’alphabétisation algorithmique est fondamentale. Autrement dit, il faut comprendre le fonctionnement des algorithmes : les usagers devraient être armés pour tester de façon indépendante les contours de leur propre bulle de filtrage et découvrir eux-mêmes comment les algorithmes de personnalisation affectent leur expérience digitale. En mettant à disposition des usagers des instruments de contrôle des algorithmes faciles à manipuler, les usagers pourront passer de l’hypothétique à la vie réelle et juger par eux-mêmes. En favorisant la prise de conscience, l’alphabétisation algorithmique va promouvoir un “régime” informationnel sain et encourager chaque usager à se responsabiliser lorsqu’il utilise les réseaux sociaux.
- Tous les instruments de contrôle des algorithmes devraient faire des analyses des algorithmes sans pour autant tracer les comportements individuels des utilisateurs. De plus, puisque la personnalisation algorithmique ne devient visible qu’à partir de la comparaison des données de chaque individu, ces instruments devraient être capables de rassembler les données provenant de différents usagers. Il est primordial que les protocoles du recueil et de réutilisation des données protègent les usagers et leurs données, tout en étayant l’analyse des données dans l’intérêt public.
- Les usagers devraient avoir la maîtrise totale des protocoles d’extraction des données, et être capables de décider à tout moment s’ils souhaitent offrir leurs données ou pas. De la même manière, ils devraient être capables de retirer leur participation quand ils le souhaitent.
- Enfin, tous les instruments de souveraineté algorithmique devraient être open-source afin de promouvoir la transparence de leurs fonctionnement, ce qui permettrait aux autres de tester, vérifier et faire évoluer ce fonctionnement, le modifier ou le personnaliser.
Nous sommes à la recherche dans de différents pays de l’UE de volontaires qui nous aident à mener une expérience sur la sélection algorithmique pendant les élections européennes. Pour manifester votre intérêt, contactez: info@algorithms.exposed
Pour en savoir plus: https://facebook.tracking.exposed
Umberto Boschi, Federico Sarchi, Popping the Bubble, The Progressive Post
Claudio Agosti, Stefania Milan, Personalisation algorithms and elections: breaking free of the filter bubble, Internet Policy Review
Remerciements: Ce projet a été financé par le Conseil Européen de la recherche dans le cadre du programme Horizon 2020, Recherche et Innovation (financement No 825974-ALEX. Responsable principale : Stefania Milan).. Pour en savoir plus, contactez: info@algorithms.exposed
(1) Les textes ont été traduits par Elena Battaglia, Cécile Martin, Jeon Sangwan sous la supervision de Giuditta Caliendo