




Agrandissement : Illustration 1

Contrairement à une Intelligence Artificielle (IA), une intelligence animale remplace son ignorance par des émotions : craindre ou espérer (faute de comprendre). Pour beaucoup, l'IA est soit le seuil d'un enfer technologique où tous les citoyens seront évalués automatiquement pour améliorer leurs comportements sociaux, ou bien, un paradis libéré du travail par des robots intelligents. Cet enfer et ce paradis sont déjà arrivés. Ainsi, pas besoin d'attendre la surveillance généralisée en Chine, 2 milliards d'humains ont abandonné avec délices leur vie privée à Facebook. Et pour la société de loisirs, le robot aspirateur existe déjà, et pourtant, les femmes de ménage dans les trains, les hôtels, ou les cabines de bateaux, sont moins chères et plus souples que des robots. L'agitation de ces marottes ne dit rien de ce que l'IA est et peut vraiment.
L'enfer de l'Intelligence Artificielle existe déjà : Facebook, 2 milliards d'humains surveillés
Les plus grands experts peinent encore à démontrer ce qui se passe dans un réseau de neurones artificiels, ce qui peut susciter des fantasmes, mais restons raisonnables, ce que l'on y fait rentrer, et ce qui en sort, tout le monde peut le comprendre. Ces technologies nous deviendront aussi intuitives que par exemple le moteur électrique, une puissance miraculeuse pour toute société pré-industrielle, mais dont il suffit de débrancher la prise pour le calmer. Notre intelligence de cervelle est ainsi faîte qu'elle apprivoise tout ce à quoi elle survit. Au lieu de spéculer sur ce qui se tramerait dans des laboratoires secrets, lisons les papiers, et faisons tourner le code publié.
Depuis 1997, la bibliothèque Nationale de France numérise ses collections pour le site en ligne Gallica, elle en arrive aux journaux (surtout avant 1945), et notamment, L'Humanité (1904-1939). Derrière les images, un texte a été obtenu automatiquement, pour le moteur de recherche. Des zones ont été retrouvées automatiquement pour que les colonnes se suivent, belle performance, même s'il reste des coquilles. Le texte du corpus complet n'est pas simplement téléchargeable, mais il est disponible sur un site européen qui a contribué au financement (à la condition d'une licence libre).

Agrandissement : Illustration 2

Comment ne pas lire des millions de livres (et en retenir tout de même quelque chose) ? Depuis Internet et la numérisation de masse, tout esprit curieux ne peut qu'être fasciné par cette masse de connaissance dont il n'aura jamais le temps de tirer l'essentiel. Notre espérance de vie n'explose pas avec le progrès technique, pas plus que notre vitesse de lecture ou la fatigue de nos yeux. Par contre, un ordinateur abordable peut traverser des kilomètres de caractères. Mais pour en faire quoi ? Les moteurs de recherche retrouvent ce qu'on leur demande, mais ils ne donnent pas une idée générale du contenu. Ce problème est ancien, l'IA se branche derrière une longue tradition, dont certains développements se firent en France.
La gauche cite souvent La Distinction de Bourdieu, on ne sait pas toujours que les conclusions qualitatives s'appuient sur une solide analyse de données quantitatives, et notamment, l’analyse des correspondances inventée par Jean-Paul Benzécri. Ce statisticien a fondé l'école française d'analyse de données (1960-1990), en dirigeant notamment la collection Pratique de l'analyse des données, dont le tome 3 porte sur Linguistique et lexicologie (1982). Le rapport entre statistiques sociales et linguistique ne semble pas immédiat, le comprendre permet de poser un problème où l'IA a un apport.
Soit une population. On peut en connaître beaucoup de choses, par exemple la taille, le poids, l'âge, le revenu, le niveau scolaire... Mais comment l'intelligence peut se représenter autant de dimensions ? On peut assez facilement tracer un graphique de répartition d'une population selon une variable, pour par exemple observer les poids les plus fréquents, et tirer quelques chiffres utiles comme la moyenne, la médiane, ou l'écart-type. Les statistiques à 2 variables s'enseignent aussi au lycée, et sont disponibles dans un tableur, pour par exemple projeter la population dans un nuages de points selon poids et taille. À 3 variables, on peut observer dans l'espace, mais avec 4, 5, ou n ?
Et si un problème majeur de santé publique comme l'obésité était corrélé au niveau de formation, pourquoi rationner les études avec ParcourSup ?
Ce problème n'est pas purement théorique, on voit bien l'intérêt de trouver un moyen mathématique d'observer toutes ces données, pour par exemple déterminer si c'est plutôt le niveau de revenu, ou le niveau de diplôme, qui est le plus corrélé à l'obésité. Il y a des décisions politiques à en tirer, par exemple, faut-il dissuader les étudiants d'entrer en sport à l'université ? Est-ce que cela ne profite pas à la société d'avoir des jeunes formés à ce qu'ils aiment, même s'ils n'y trouvent pas de travail, pour les avoir plus heureux et en meilleure santé ?
Le problème mathématique à résoudre relève des espaces à dimensions multiples. Soit des individus qualifiés par 25 paramètres, ils peuvent devenir des points dans un espace à 25 dimensions, mais qu'est-ce qu'un humain peut voir dans ce nuage ? Comme un cube dont on ne peut pas voir les 6 faces à la fois, on le tourne pour trouver la vue la plus significative, voilà l'intuition principale des analyses des correspondances. Soit maintenant un corpus de textes, on peut dire que chaque mot peut devenir une variable statistique comme le poids ou la taille. La langue est alors un espace avec autant de dimensions que de mots dans le lexique. Cette hypothèse du modèle vectoriel date des années 1960, elle continue à montrer une grande efficacité dans le traitement automatique du texte. L'innovation consiste à trouver des procédés nouveaux pour rendre lisible à des humains ce qui peut se calculer dans ces espaces multidimensionnels.
Si nous n'avons pas le temps de lire 7 328 numéros de L'Humanité de 1919 à 1938, que voudrions-nous en retenir ? Beaucoup de faits du moment s'oublieront, comme nous ne retenons pas chaque seconde de notre vie, mais on pourrait se demander si les mots avaient à l'époque le même sens qu'aujourd'hui, et s'ils avaient le même sens dans tous les journaux, par exemple Le (petit) Parisien, Le Temps (équivalent à Le Monde aujourd'hui), La Croix, Le Figaro, ou L'Action Française (quotidien royaliste de Charles Maurras). À part l'Action Française, ces lignes éditoriales persistent et restent lisibles aujourd'hui. Ce corpus de middle-data (1,5 milliards de mots) a l'avantage d'être doublement structuré, par la date, et par le titre, dont les variations connues permettront de mieux comprendre ce que peuvent apporter ces algorithmes.
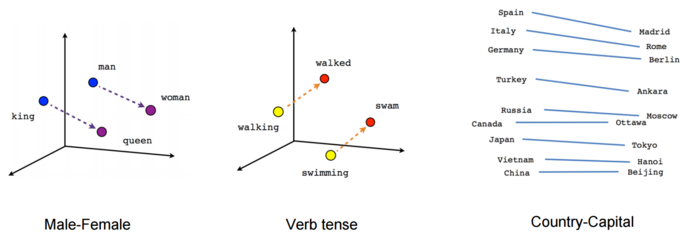
Agrandissement : Illustration 3

Soit l'hypothèse qu'un mot prend son sens par les mots qui l'entourent (5 avant et 5 après suffisent, taille approximative de la mémoire immédiate). On pourrait dire que le sens d'un mot est défini par tous ses voisins. Il en résulte que tout mot peut être exactement caractérisé par un vecteur unique dans l'espace multidimensionnel du lexique. Il ne s'agit pas ici de définitions, mais des emplois, avec parfois un décalage entre l'idée que l'on se fait d'un mot, et la manière dont il est employé.
Depuis Mikolov (Google, 2013, word2vec), une communauté de linguistes pense avoir trouvé la recette magique pour constituer automatiquement des bases de connaissances avec des corpus énormes. Si la langue peut être projetée dans un espace euclidien (multidimensionnel), alors chaque mot est un vecteur obéissant à une algèbre, retrouvant une proportionnalité presque platonicienne entre les concepts où l'on pourrait par exemple calculer qu'une reine est à un roi ce qu'une femme est à un homme. Constituer de telles bases sémantiques sans intelligence humaine est un enjeu économique et industriel. Cela permettrait par exemple d'éviter l'établissement de dictionnaires de synonymes interconnectés entre toutes les langues pour la traduction automatique. Les résultats sont impressionnants, mais ne peuvent pas dire autre chose que les corpus poussés en entrée.
- Presse 1919-1938, word2vec (Mikolov, Google), mots proches par le contexte (-5, +5 mots, CBOW), penser : objecter, croire, dire, savoir, songer, vouloir, imaginer, étonner, peut-être, pourquoi, ajouter, douter, parce que, mais, n'est-ce pas, puisque, donc, espérer, oublier, supposer...
Ainsi par exemple, dans notre corpus de presse d'Entre-deux-Guerres, les mots qui sont employés de la même manière que le verbe penser ne sont pas ses synonymes recensés dans les dictionnaires (concevoir, réfléchir, méditer...), mais plutôt des verbes de communication : objecter, croire, dire... Dans un journal, quand quelqu'un pense quelque chose, il est en train de le dire, c'est en tous cas écrit. Le genre d'un texte modifie le sens des mots.
Cette simple expérience suffit à montrer le biais de tout corpus, et la vanité des prétentions des firmes à en savoir plus en augmentant les masses. Quelques milliards de Google news supplémentaires n'en diront pas plus sur l'intelligence et la pensée que le style conventionnel de la dépêche de presse. Il ne suffit pas d'augmenter les data pour en savoir plus, passé un seuil, le rendement de la masse baisse rapidement. On produit parait-il plus de données en 2 ans que depuis les derniers millénaires de l'histoire, mais la masse de Facebook ne vaut à peu près rien, comparée aux textes grecs et latins. Par sa distance, l'expérience humaine conservée par les antiquités gréco-romaines nous en apprend plus sur l'universel que la réplication numérique de notre banalité.
- Presse 1919-1938, Alix (Glorieux), mots proches par le contexte (-5, +5 mots), penser : croire, ajouter, dire, savoir, alors, espérer, prétendre, souhaiter, estimer, affirmer, bien, prouver, supposer, répéter, imaginer, vouloir, craindre, insinuer, raconter, regretter, signifier...
Mais est-ce bien nécessaire d'avoir attendu 2013, les réseaux de neurones, et Google pour calculer des vecteurs de mots ? Le résultat ci-dessus est obtenu de manière plus naïve et semble convaincant. Il pose pourtant déjà des problèmes. Le corpus comporte environ 50 000 mots différents avec plus de 5 occurrences (les mots plus rares ne permettent pas des calculs significatifs). Pour enregistrer les co-occurrences, c'est-à-dire les rencontres de mots dans un même contexte, l'approche spontanée consiste à ouvrir un tableau avec 50 000 lignes et 50 000 colonnes, et à augmenter les cases au fur et à mesure qu'un automate traverse le textes. Le mot le plus fréquent (le) ayant plus de 100 millions d'occurrences, il faut au moins 4 octets pour chaque case, la matrice pèse 10 Go en mémoire.
Toutefois, 98,5 % des cases sont vides, la majorité des mots ne se rencontrent jamais ensemble. Par exemple, dans un journal, les faits divers se mélangent rarement avec la chronique boursière (martyriser et dividendes). Un réseau de neurones se contente de beaucoup moins de mémoire (0,65 Go). Cette sobriété s'explique par le principe même des réseaux de neurones. Word2vec a 3 couches, une en entrée, de la taille du vocabulaire (50 000), une couche cachée, qui a entre 100 et 300 nœuds, et une couche en sortie, pour retrouver le vocabulaire (50 000). Il en résulte que l'espace vectoriel n'est plus défini par les 50 000 dimensions du vocabulaire, mais 100 à 300 dimensions arbitraires, qui diminuent la quantité d'information à stocker. On retrouve le type de problématique de Benzékri, la réduction des dimensions, mais est-ce que cela n'abîme pas l'information sémantique ?
- Presse 1919-1938, Alix, vert : rouge, noir, bleu, blanc, sec, mou, poire, divers, mouler, cuit, ferme, antennes, courge....
- Presse 1919-1938, word2vec, vert : bleu, violet, blanc, rose, orangé, gris, écarlate, doré, noir, mordoré, cerise, ocre, verdâtre, jaune, foncé, violacé, rouge, mauve, amarante, turquoise, ocres, grisâtre, safran, couleur, iris, ramages, jade, indigo, border, fleurettes, brun...
La réduction du nombre de dimensions augmente fortement la précision de l'espace lexical. On le voit ci-dessus sur un adjectif de couleur (vert), les performances de l'algorithme naïf méritent déjà l'intérêt, mais word2vec est autrement plus performant. Dans l'espace à 50 000 dimensions, le vecteur des mots très fréquents ont tendance à écraser les autres. De plus, cet espace n'est pas algébrique, il n'est pas possible de calculer des analogies (un homme est à une femme ce qu'un roi est à : reine, reine_mère, impératrice, princesse, archiduchesse....). La réduction du nombre de dimensions apportent donc beaucoup à l'espace lexical.
Mais est-ce qu'un réseau neuronal est nécessaire pour normaliser l'espace vectoriel du lexique ? Mikolov a été rapidement contesté, notamment par Chris Manning (Stanford, GloVe), qui obtient de meilleurs résultats avec une approche déterministe de normalisation des vecteurs, optimisée pour les analogies. Sa critique vaut la peine d'être méditée. Un réseau neuronal fonctionne par entraînement. En fonction de ce qu'il a appris du texte déjà vu, il tente des hypothèses sur le mot qu'il pense trouver, et ordonne ses neurones en fonction de ses essais et erreurs. Il en résulte qu'un entraînement est une histoire, qu'un état résulte du précédent et ainsi de suite, avec une semence aléatoire (les hypothèses), si bien que chaque entraînement pourra donner des résultats différents. Pour des tâches simples, comme choisir entre freiner ou tourner quand un vélo traverse, le risque de variation est faible, mais pour un moteur d'analyse sémantique, les possibilités de contresens sont élevées dans les marges.
Les réseaux de neurones, des algorithmes qui vont se généraliser, comme auparavant les tables de hachage
Mais GloVe n'a pas donné de bons résultats pour ce corpus de presse, sous dimensionné relativement à la taille pour laquelle l'algorithme est prévu. De plus, l'entraînement a pris beaucoup de mémoire, partant de la matrice à 10 Go. Un autre compétiteur est réputé, WordRank (Intel, Amazon), mais comme l'entraînement sur le corpus dure plus de 24 heures, l'approche est de toute façon à exclure, parce qu'elle ne permet pas de multiplier les essais pour trouver les meilleurs réglages. Par ailleurs, ces optimisations déterministes sont toujours spécialisées pour le problème, elles demandent un bon niveau mathématiques, alors que les réseaux de neurones sont une solution générique qui règlent bien d'autres problèmes flous, comme par exemple la détection de la pornographie dans les images.
Les réseaux neuronaux ont été inventés dans les années 1980, mais prennent une actualité depuis 2012 pour plusieurs raisons. La quantité de données d'entraînement augmente, de même la puissance et le nombre de processeurs (une carte graphique d'ordinateur pour les jeux peut en contenir plus de 100), mais surtout, ces IA arrivent en bout de chaîne de problèmes déjà très formalisés, comme ici la réduction du nombre de dimensions d'un espace vectoriel. Une fois que des entrées et des sorties peuvent se formaliser en une série de nombres, l'entraînement d'une IA peut remplacer beaucoup de programmation plus laborieuse.
L'informatique a déjà eu ce genre de révolutions dans son histoire. Ainsi par le passé, un informaticien était formé aux structure de données et aux algorithmes (tris, recherches...), selon la bible établie par Donald Knuth, The Art of Computer Programming. Désormais, les meilleurs algorithmes sont nativement disponibles dans les langages, et notamment, les dictionnaires (HashMap). Cette structure de données a révolutionné les performances informatiques, parce qu'elle permet de rechercher dans une liste à temps constant (ou presque), permettant de retrouver très rapidement des mots ou des chiffres dans des très grandes listes. Les HashMap sont omniprésents, dans les moteurs de recherche, pour gérer les noms de variables dans l'exécution d'un programme, ou bien pour les adresses Internet. Les réseaux de neurones sont appelés à se généraliser et à produire autant d'effets.
Word2vec devrait donc nous permettre de comparer L'Humanité à d'autres quotidiens de l'époque. La première surprise, c'est que la plupart des mots ont un sens (vecteur) proche dans chaque titre. Les mots grammaticaux (de, le, la...) ne vont bien sûr pas varier, ils tiennent beaucoup plus de la langue que du contexte, de même les verbes. Il faut tout de même chercher longtemps pour trouver des substantifs dont les emplois sont différents.
Ainsi, le travail dans L'Humanité est proche de : labeur, embauchage, travailler, salaire, travaux, ouvriers, apprentissage, demi-journées, corporation, embauche, salaires, trois-huit, trimer... Dans Le Figaro, nous n'assistons pas encore au renversement libéral des valeurs, le travail reste difficile : labeur, travaux, ouvriers, travailleurs, travailler, chômage, besogne, patronat, patrons, patronal, ouvrières, travailleur, fonctionnement... Les deux journaux parlent de la même chose, le labeur, selon leur point de vue (L'Humanité : salaires, Le Figaro : patrons).
«Capital», mots voisins sur des quotidiens de 1919 à 1938
- L'Humanité : capitalisme, oligarchie, trusts, féodalité, bourgeoisie, capitalistes, capitaliser, banques, parasitisme, trust, ploutocratie, profits, finance...
- Le Petit Parisien : dividende, actionnaires, actions, capitalisation, assurances-vie, cumulatif, escudos, obligataire, souscrit, acompte, statutaire...
- La Croix : dividendes, capitaux, actionnaires, bénéfices, actionnaire, prélèvement, obligataire, épargne, capitaliser, tantièmes, hypothécaire, fortunes, rémunération...
- Le Temps : actions, immobilisations, société, actionnaires, obligataire, commanditer, statutaire, apport, filial, numéraire, millions, prélèvement, dividendes...
- Le Figaro : dividendes, actions, dividende, bénéfices, immobilisations, actionnaires, répartitions, prélèvement, millions, capitaliser, souscrit, montant, obligataire...
- L'Action Française : actions, actionnaires, parts, nominal, dividendes, affinage, obligataire, triphasé, dividende, salines, régulariser, société
Mais on voit ci-dessus qu'un concept comme le capital a un sens spécial pour le lecteur de L'Humanité. Il n'a pas assez d'épargne pour se soucier de dividendes et de bénéfices, par contre, il voit bien à qui profite la pression sur son salaire : oligarchie, féodalité, ploutocratie... Tous les autres titres du corpus partagent le point de vue du Figaro, même Le Petit Parisien, censé être un journal populaire. On comprend comment s'installe une norme dans les mots. Le capital est d'abord une masse monétaire qui peut être investie dans une entreprise, il suffit de limiter le périmètre des faits pour ne jamais en tirer les conséquences sur la société. Un lecteur du Parisien lira les chroniques financières comme un reportage dans les colonies, et il s'irritera de L'Humanité, pas amusant, trop «politique». Il suffit qu'un journal continue à plaire à son public pour qu'il l'entretienne dans son opinion en ignorant celle des autres. Hier comme aujourd'hui, il suffit de répéter un monde plausible et plaisant pour conserver chacun dans sa bulle idéologique et son réseau social, en évitant le désagrément de prendre conscience.
L'orientation d'un journal se cristallise donc sur quelques mots, pas nécessairement les plus fréquents, mais ceux auxquels un sens différent est donné. Nous voudrions dès lors savoir quels sont ces mots divergents qui donnent la direction idéologique de chaque journal. Théoriquement, il aurait suffit de comparer le vecteur d'un mot dans un journal, avec celui dans la totalité du corpus, pour dégager les plus divergents. En pratique, le résultat n'a rien donné, parce que l'espace vectoriel produit avec des réseaux neuronaux est entièrement singulier. Même avec le même corpus, l'effet cumulatif des semences aléatoires produit pour chaque mot des vecteurs incomparables d'un espace à un autre (mais les mots d'un même espace restent cohérents entre eux). Cette expérience aura montré la force, et les limites, des réseaux neuronaux, invitant à reprendre la copie des mathématiques déterministes pour réduire une matrice creuse.
Plus concrètement, cette expérience montre un changement tout à fait important dans l'histoire de l'informatique. Jusqu'ici, les progrès portaient sur des avancées dans les algorithmes qui en eux-mêmes résolvaient des problèmes. Or, la difficulté intellectuelle de produire un bon programme a montré la supériorité de l'organisation sociale du logiciel libre. C'est une menace latente sur le profit des compagnies qui sont actuellement les plus grandes capitalisations boursières.
L'engouement pour les réseaux de neurones ne s'explique pas seulement par leur puissance. Certes, ils résolvent des problèmes jusque là insolubles avec de l'algorithmie déterministe, par exemple, la reconnaissance de la parole ou des visages. Mais il y a surtout un intérêt économique pour les grandes firmes. La force d'une IA n'est pas son algorithme, les meilleures librairies sont publiées librement par Facebook ou Google, car ils ne craignent pas la concurrence. Les chercheurs peuvent rivaliser d'astuce pour concevoir les meilleures architectures neuronales dans leurs articles, de toute façon à la fin, ce seront les propriétaires de données qui feront le profit.
L'objectif va donc être de faire croire que les IAs demandent de lourdes puissances de calcul, si bien que les firmes garderont les modèles entraînés dans leurs nuages (cloud), ne vendant que le résultat de cet entraînement, et obtenant en échanges les données pour parfaire leurs modèles. La captivité de l'utilisateur va augmenter.
Alors, que faire ?
- jeter son smartphone,
- n'utiliser que des logiciels qui marchent hors ligne,
- lire les articles et expérimenter les IAs dans ses domaines de compétences,
- retrouver des résultats aussi bons avec des algos déterministes,
- optimiser son code pour économiser l'énergie et la planète.
Il est désagréable de se quitter sur un échec, même s'il est instructif. En attendant de trouver une meilleure formule pour optimiser l'espace lexical d'un corpus, appréciez un résultat beaucoup plus élémentaires.
Titres comparés à L'Humanité (1919-1938), mots en ordre de fréquence de Titre
1) au moins 3x plus fréquent dans Titre
2) au moins 3x plus fréquent dans L'Humanité
- Le Petit Parisien, 1) monsieur, parisien, madame, messieurs, mademoiselle, vins, crédit, bail, amour, matinée, joli, hôtel, dame, vouer, valeurs, dames, jardin, loger, titres, salon, prés... 2) travail, parti, comité, salle, action, congrès, réunion, ouvriers, mouvement, ouvrier, classe, délégués, populaire, socialiste, front, organisation, usines, peuple, syndicat, lutte...
- La Croix, 1) monseigneur, église, Dieu, abbé, catholique, saint, croix, religieux, catholiques, chrétien, mademoiselle, cardinal, dame, évêque, ouverture, œuvres, curé... 2) travail, parti, comité, ouvriers, hier, réunion, salle, classe, ouvrier, fédération, front, lutte...
- Le Temps, 1) messieurs, banque, nations, crédit, traité, marché, correspondant, valeurs, commercial, clôture, longueur, tonnes, parts, exercice, foncier, relatif, alliés, actions, eaux, télégraphier, royal, réparations, obligations, mesdames, ... 2) travail, réunion, salle, ouvriers, fédération, battre, populaire, front, classe, lutte...
- Le Figaro, 1) monsieur, madame, mademoiselle, messieurs, comte, comtesse, hôtel, honneur, mesdames, château, revue, confort, opéra, cuire, dame, parc, baron, matinée, fille, moderne, pari, royal, église, annonces, exposition, baronne, téléphone, clôture, marquise... 2) contre, travail, comité, action, réunion, classe, congrès, fédération, mouvement, bourgeois, ouvriers, chefs, travailler, populaire, organisation, socialiste, front, lutte...
- L'Action Française, 1) roi, mademoiselle, église, duc, matinée, dames, comte, partant, monseigneur, commandant, royal, alliés, anonyme, valeurs, courses, camelots, ligueurs, patrie, arts, royalistes, siècle, abbé, salon, vins, rois, lieutenant, âme, catholiques, études... 2) parti, travail, comité, ouvriers, congrès, classe, communistes, grève, lutte...
En comparant deux à deux les journaux, on peut relever automatiquement les mots spécialement plus fréquents relativement à l'un à l'autre. Par rapport à L'Humanité, Le Petit Parisien parle plus de vie quotidienne et de consommation, La Croix de l'Église, Le Temps des marchés et de politique internationale, Le Figaro de littérature et de mondanité, L'Action Française de royalisme.
L'Humanité se distingue de tous les autres journaux comme l'organe du parti ouvrier, annonçant les réunions et les actions de l'ouvriérisme combattant. Est-ce que les femmes lisaient L'Humanité ? On rapporte que les partis de gauche sont restés réticents sur le droit de vote des femmes, craignant qu'elles écoutent plus le curé que le journal. Dans L'Humanité d'alors, le vocabulaire de la famille et du ménage est surtout associé à la misère. Le Figaro parle de bonnes et de servantes comme une évidence universelle, mais Le Petit Parisien, journal populaire, était le véritable adversaire politique de la gauche, en parlant de cuisine, de loisir, d'amour, continuant une littérature populaire pour les femmes, très vivace à l'époque. Cette culture n'était certainement pas émancipatrice, mais elle était plaisante.
Conclusions
L'espace vectoriel multidimensionnel reste un modèle très convaincant pour représenter le lexique, et l'on peut ajouter qu'il suffit de quelques centaines de neurones pour retenir les 50 000 mots d'un dictionnaire, et d'en distinguer les sens, sous forme de vecteurs. Mais avec 100 milliards de neurones, notre cerveau peut très bien entretenir plusieurs modèles concurrents du langage. L'espace est approprié pour choisir ses verbes avec nuance, mais pour un concept, des informations manqueront, ainsi, le vecteur de baleine est proche de squale, cétacé, poisson, sardine, baudroie... mais il ne dit pas qu'une baleine est un mammifère. Espace vectoriel, arbres de concepts, mais aussi chaînes syntaxiques, aucun modèle artificiel n'épuise la langue. Les vecteurs donnent en tous cas plus de force à ces métaphores familières, et pourtant étranges dès que l'on y pense un peu, comme la ligne d'un journal, ou le sens d'un mot, aussi bien direction que signification.
Les réseaux de neurones vont probablement bousculer quelques pratiques et hiérarchies dans le développement informatique, au risque de conforter l'emprise des grandes firmes. Leur plus grande puissance est certainement de pouvoir attirer les esprits les plus libres. À tous ceux qui n'ont pas été pris, nous sommes assez pour être meilleurs. Deux médiocres valent plus qu'un bon, dès lors qu'ils s'entendent, car le secret de l'intelligence humaine est justement l'entente. L'IA a bien d'autres usages que le profit, elle est plus simple que ce qu'elle remplace, elle ne demande pas des puissances de machines inaccessibles au particulier.
Enfin, l'expérience conduit à quelques réflexions politiques. Une idéologie, surtout lorsqu'elle se dit révolutionnaire, se pense comme une vision globale de la société et de l'humain. Un journal, particulièrement dans l'Entre-deux-Guerres, est un vecteur d'expression politique. Pourtant, le lexique ne varie qu'à la marge. Ce qui est partagé est beaucoup plus important que ce qui distingue. D'abord, c'est la même langue, avec une forte pression de la syntaxe sur les mots les plus fréquents. Ensuite, les journaux sont des écrits publics, destinés à être compris par tous les citoyens. Ils traitent du même sujet, l'actualité, si bien qu'ils partagent beaucoup de vocabulaire, contrairement à par exemple des écrits scientifiques de disciplines différentes. Il en résulte qu'un journal se distingue politiquement d'un autre par assez peu de traits. On observe notamment que tous les titres n'ont pas chacun une opinion différente sur tout, un journal se distingue surtout par la hiérarchisation de ses sujets.
L'expérience doit encore être poursuivie, afin de mesurer objectivement les mots qui finissent par signifier vraiment autrement dans le contexte d'un journal. Il ne faut pas en attendre un renversement de ce que l'on sait des opinions de l'époque, mais des surprises dans les marges. Au lecteur qui n'est pas familier de ce genre de méthodes, l'argument de ce billet relève des Humanités Numériques. Si votre bon sens a été convaincu, soyez assuré que la démarche est rigoureuse. Si vous ne l'êtes pas, inutile d'ajouter des notes de bas de pages, de la bibliographie, des formules mathématiques, ou plus de prudence dans l'expression. Ces habitudes universitaires ont envahi l'époque, elles excluent trop de monde de la discussion, même les universitaires n'osent plus s'aventurer en dehors de leur spécialité. Il y a une expression à trouver qui ne tait rien des nuances, mais qui donne à chacun le moyen de ne pas être d'accord.