



Après avoir essayé en vain de redresser la situation d’AgoraVox avec le groupe Amélioravox, j’ai entrepris de réaliser un nouveau site de «journalisme libre.

Agrandissement : Illustration 1

La production de code et l’implantation du site proprement dite se fera en moins d'une année. Cette phase finale sera précédée d’une longue phase de préparation avec un travail d’analyse et un choix d’outils performants dont il faudra acquérir la maîtrise.
Il s'agit de concevoir une application web relativement complexe. La complexité vient notamment de la multiplicité des catégories de membres qui n'ont pas les mêmes attributions et, de plus, celles-ci évoluent (super-administrateurs, administrateurs, membres du comité éditorial, sélectionneurs, auteurs, candidats-auteurs, commentateurs, visiteurs). Nous avons actuellement deux exemples en France d'applications de journalisme libre avec AgoraVox et Bellaciao. En vous reportant à la Charte que nous proposons, vous constaterez que notre proposition se distingue sur divers points de ces applications. De plus, les implantations déjà anciennes de ces deux sites nécessiteraient des mises à jour. Ce sera donc l’occasion aussi de réaliser un site techniquement mieux conçu.

Agrandissement : Illustration 2

La réalisation de ce site étant complexe, j’ai décidé de commencer par mettre en place un site plus simple qui évoluera. Au départ, il s’agira simplement d’un blog multi-auteurs ouvert aux commentaires. Ce sera beaucoup plus simple car il n’y aura pas de procédure de sélection des articles, d’envois de notifications... Tous les auteurs participants au site pourront publier autant d’articles qu’ils le veulent et quand ils le veulent. La sélection se fera donc dans le choix des auteurs. Les nouveaux auteurs seront cooptés par ceux qui seront déjà en place.
Je me charge du recrutement des premiers auteurs. Pour l’instant, je fais cette proposition à des auteurs qui ont publié au moins 15 articles sur AgoraVox. Ils doivent aussi avoir montré à la fois qu’ils savent écrire des articles de bonne qualité et qu’ils savent discuter en respectant les règles de bonne conduite de notre charte. Il faut qu’ils soient d’accord avec les grands principes de liberté d’expression et d’exigence de vérité de la charte. J’espère que ce site pourra ainsi rassembler des auteurs de sensibilités différentes. Ce sera ce qui nous distinguera de nombreux sites multi-auteurs qui ont tous une ligne éditoriale précise. Nous devrions ainsi montrer qu’il est possible, avec un tel site, de confronter sereinement des points de vue différents et que cela est bénéfique pour tous.
En évoluant, le site passera par une période intermédiaire où des articles seront proposés par les utilisateurs et une sélection sera faite en visioconférence par les auteurs-sélectionneurs. Puis tous les articles suivront la même procédure de sélection. Nous arriverons alors au site prévu par notre Charte. Puisqu’on prévoit à l’avance cette évolution, il faut démarrer avec une conception du site dans sa version finale laquelle sera simplifiée pour les premières implantations.
Au départ, le travail de conception se fera donc sur la version la plus complexe et l’implantation sur la version la plus simple. Ce travail de conception portera principalement sur l’interface utilisateur et la structure de la table des données.
Les frameworks et autres outils
Avant tout travail de programmation, il faut choisir les outils que nous utiliserons.
Les grands principes du génie logiciel s’appliquent à la conception des sites web. Il est maintenant rare que les concepteurs s’en tiennent aux langages formels d’origine comme l’HTML et le CSS, ni même d’ailleurs aux deux langages de programmation : le Javascript et le PHP.
Rappelons la différence essentielle entre ces deux langages qui ont en commun d’être des langages interprétés. Un interpréteur de Javascript est implanté dans chaque navigateur. Les navigateurs ont parfois des modèles de « texte-hypertexte » légèrement différents et il faut tenir compte de ces différences pour que le code écrit en Javascript puisse être interprété convenablement quel que soit le navigateur du client. Le PHP est implanté sur le serveur. Les questions de compatibilité ne se posent donc pas pour ce langage. Le code doit être conforme à l’interpréteur PHP du serveur qui héberge l’application. En général les développeurs installent un serveur local sur leur ordinateur personnel pour simuler ce que fera le serveur du prestataire lorsqu’ils y transfèreront l’ensemble de l’application avec sa base de données. Le langage PHP est indispensable pour toutes les applications qui ont besoin d’une base de données. C’est avec le PHP que sont envoyées les requêtes SQL. Une application web nécessite donc la mise en œuvre de ces deux langages. Le Javascript intervient sur le client et le PHP sur le serveur. Dans le premier cas on parle de « front-end » et dans le second cas de « back-end ».
Cependant, ce que je viens d’écrire doit maintenant être nuancé avec l’apparition de « node.js ». Il s’agit d’un environnement d’exécution de Javascript en dehors du navigateur. Node.js intervient dans la mise en place de divers frameworks sans être lui-même un framework. Disposant ainsi d’un interpréteur de Javascript hors du navigateur, il devient possible de programmer du back-end en Javascript. Node.js propose en plus 13 librairies.
Nous retrouverons les termes front-end et back-end à propos des frameworks qui seront orientés soit pour l’un soit pour l’autre. L’appellation full-stack désigne la capacité d’agir à la fois sur le back-end et sur le front-end.
Chaque application internet faisant intervenir une base de données possède un développement front-end et back-end. Le front-end agit sur tout l’aspect visible du site internet, ce avec quoi l’utilisateur peut interagir directement c’est-à-dire l'interface utilisateur. Le back-end inclut la structure du site et toutes les manipulations relatives aux bases de données. C'est donc l'arrière-plan invisible pour l’utilisateur.
Le temps où les concepteurs d’applications web se contentaient de ces deux langages de programmation (Javascript et PHP) est révolu. Afin de ne pas refaire sans arrêt le même travail, des frameworks ont été conçus au même titre que des bibliothèques (ou librairie) existent avec d’autres langages. Prenons un exemple bien connu. Dans des milliers d’applications web les utilisateurs peuvent être de simples visiteurs mais ils peuvent aussi être invités à s’inscrire pour ensuite se loguer. Cela leur permet d’accéder à des fonctionnalités supplémentaires par rapport au simple visiteur. Typiquement, ils peuvent commenter les articles qu’ils lisent sur un blog. Des milliers d’applications web ont pour cela toute une procédure d’inscription et d’authentification. Le recours à un framework dispensera le développeur d’avoir à écrire tout le code nécessaire pour cela.
L’expression « plate-forme de développement » est aussi parfois utilisée pour désigner un framework ou un ensemble de frameworks cohérent avec éventuellement d’autres outils comme « l’environnement de programmation » du développeur. L’environnement de programmation comprend le serveur local installé sur l’ordinateur du développeur et les langages et interpréteurs dont il a besoin. Le développeur installe généralement tout un package qui contient l’ensemble de ces outils (Wamp, Laragon…).
Un framework contient essentiellement un ensemble de bibliothèques, d'outils, de conventions de codage et de modèles de conception qui simplifient et accélèrent le processus de développement logiciel. Il fournit généralement une structure sur laquelle les développeurs peuvent construire leurs applications sans avoir à réinventer chaque composant.
En d'autres termes, un framework offre une base sur laquelle un développeur peut construire des applications en se concentrant sur l’analyse conceptuelle davantage que sur les aspects techniques. Une bonne partie des questions techniques est en effet traitée d’emblée par les frameworks.Voici quelques avantages liés à l’utilisation des frameworks :
- Les frameworks offrent une approche structurée pour le développement, ce qui permet de gagner du temps. Les développeurs n'ont pas besoin de créer chaque composant individuellement, car de nombreuses fonctionnalités courantes sont déjà intégrées dans le framework. Les frameworks peuvent également incorporer des bibliothèques spécifiques pour faciliter certaines tâches. Les développeurs peuvent utiliser ces bibliothèques pour gagner du temps et éviter de réinventer la roue.
- Les frameworks permettent souvent l'intégration de modules tiers ou de plugins qui étendent encore davantage les fonctionnalités de l'application. Cela peut inclure l'intégration de bases de données, de services cloud, de services d'authentification, etc.
- Les frameworks encouragent la réutilisation du code, ce qui signifie que les développeurs peuvent utiliser des composants existants pour résoudre des problèmes similaires dans différentes parties de leur application. Cela réduit la duplication de code et facilite la maintenance.
- Les frameworks sont souvent conçus en tenant compte des meilleures pratiques en matière de sécurité. En utilisant un framework réputé, les développeurs peuvent bénéficier de fonctionnalités de sécurité intégrées qui réduisent les risques liés aux vulnérabilités.
- La structure d'un framework facilite la gestion et la maintenance à long terme d'une application. Les mises à jour et les correctifs sont généralement plus simples à appliquer lorsque vous utilisez un framework bien établi.
Il faut donc choisir un ou plusieurs frameworks. Bien connaître un framework nécessite un temps d’apprentissage qui doit être un investissement rentable pour un développeur. Le choix des frameworks correspondants aux besoins d’un développeur est primordial. Il s’agit alors pour chaque développeur de déterminer quelle catégorie de développement web il va privilégier (applications avec base de données, applications mobiles…).
C’est d’autant plus difficile que l’offre est abondante. Nous avons trouvé 64 frameworks :
Agrandissement : Illustration 3

Il faut assurément plusieurs heures pour tester sérieusement un framework. Nous n’envisageons donc pas de les tester tous. Il va falloir trouver des critères pour faire un choix sans nécessairement tout essayer.
Il faut savoir distinguer les différents types de frameworks afin de choisir judicieusement ceux qui conviennent à un projet. La connaissance d’un ou plusieurs frameworks donne une compétence spécifique aux développeurs pour un type particulier de projet. Un investissement en temps d’apprentissage permet de tirer pleinement parti de ces puissants outils de développement logiciel.
Certains frameworks sont particulièrement indiqués pour développer des applications mobiles. Ils devront donc fonctionner sur des systèmes d'exploitation tels qu'Android et IOS (ReactJS, Flutter, Meteor).
Dans notre cas, nous nous intéresserons particulièrement aux frameworks qui facilitent la création, la gestion, et la manipulation de bases de données. Ils fournissent généralement des outils pour la gestion des routes, la création de modèles de données et l'interaction avec les bases de données. Ce sont des frameworks orientés pour le back-end. On trouve parmi eux : Entity Framework, Laravel, Phénix, Django, Codelgniter, Rail, CakePHP. Le back-end gère également toutes les permissions des utilisateurs et la sécurité. Par exemple, le back-end décide de ce qu’un utilisateur peut ou ne peut pas faire en fonction de son statut. Il peut s'agir d'un utilisateur régulier plutôt que d'un administrateur, ce qui affectera ce qu'il peut voir et faire, ce qui est affiché lorsqu'un utilisateur est connecté ou déconnecté. Les systèmes back-end sont écrits dans différents langages. Par exemple Django est en Python et Rails est écrit avec Ruby. Cependant, le plus souvent ces frameworks sont écrits avec PHP qui est le langage dédié, nécessairement du côté du serveur, à la base de données. La majeure partie de « la logique lourde » et de la validation des données réside dans le back-end, qui permet de gérer les données enregistrées. Actuellement, tous les frameworks de back-end adoptent l’Architecture MVC (Modèle-Vue-Contrôleur ».
Nous nous intéresserons cependant aussi aux frameworks orientés pour le front-end. On trouve parmi eux : Angular, ReactJS, Ember, Tailwind CSS, Materialize CSS, GWT, Vue.JS. Ces frameworks sont particulièrement utiles pour développer des interfaces utilisateur dynamiques et interactives. Le front-end est en effet responsable de la gestion de l’interface utilisateur. Les frameworks front-end s'exécutent côté client et, par conséquent, sont souvent écrits en Javascript puisque JS est le langage universel parmi les navigateurs Web (clients) mais ils ont aussi amplement recours au CSS. Le front-end gère également l'apparence et la convivialité des pages, la manière dont les données sont affichées et la manière dont les éléments importants tels que les boutons et les données du formulaire sont gérés. Il influe grandement l’esthétique et l’ergonomie du site.
Même si ce n’est pas toujours judicieux, il est possible d’utiliser plusieurs frameworks pour le front-end. Il n’y a pas obligatoirement d’incompatibilité entre-elles. Il est aussi possible d’utiliser un framework pour le back-end et un ou deux autres pour le front-end. C’est même un choix judicieux. Vous pouvez avoir un site Web avec un seul framework back-end ou un seul framework front-end. Cependant, dans ce deuxième cas, le framework ne vous permettra pas de stocker et manipuler les données du serveur et vous devrez donc le faire avec PHP. Les framework front-end sont donc aussi utilisés pour les sites web qui ne gèrent pas de base de données.
Quand une application web inclut la gestion d’une base de données, il est judicieux de choisir en premier lieu le framework back-end et d’envisager ensuite d’y associer un ou plusieurs frameworks front-end.
Mais les offres disponibles ne se limitent pas à des frameworks spécialisés pour le front-end ou le back-end. Les frameworks les plus utilisés sont full-stacks. En fait, ils offrent des kits qui viennent compléter le framework de base. Ces kits sont maintenant aussi connus que les frameworks eux-mêmes. Citons-en quelques-uns : Jetstream, Breeze, Cashier (Stripe), Cashier (Paddle), Folio, Mix, Precognition, Livewire, Sanctum, Fortify, Spark, Nova, Socialite, Blade, Filament… Nous avons notamment quelques « starter kits » pour l’authentification : Laravel/UI, Breeze, Jetstream, Fortify, Sanctum et Spark. On peut ajouter Socialite qui propose une authentification à partir de celle qui est faite par des sites réputés fiables comme Google ou Amazon. Fort heureusement le choix ici est limité.
Notre choix s’orientera vers un ensemble qui permet les meilleures combinaisons entre le framework de base et les kits complémentaires qui peuvent répondre à nos besoins avec notamment un kit pour l’authentification.
Notre application de journalisme libre se caractérise par un système complexe de permissions avec des statuts d’utilisateurs variés et une base de données, elle aussi, relativement complexe. Ce sont ces caractéristiques qui orientent notre choix.
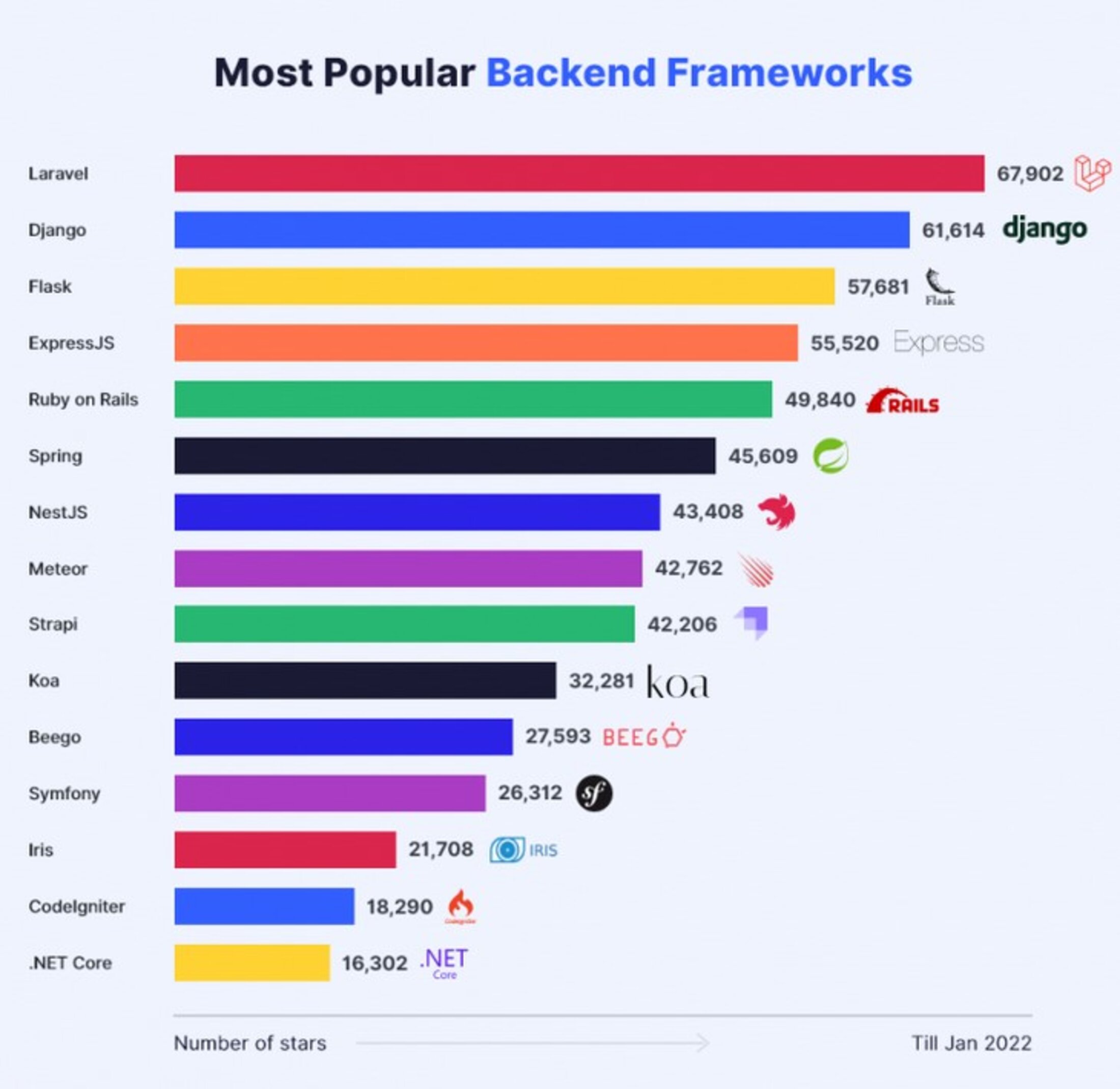
Nous tenons donc compte en premier lieu de ces caractéristiques mais, en second lieu, nous tenons compte aussi de la taille de la communauté entourant chaque framework et de son activité. Une grande communauté offre un meilleur support, des ressources et des bibliothèques tierces pour le développement, une abondante documentation… Nous nous intéressons donc aux statistiques sur l'utilisation des divers frameworks tout en nous méfiant d'éventuelles fausses statistiques qui sont, en fait, des publicités cachées. Il convient de chercher en premier lieu le framework de back-end. Nous avons consulté de nombreuses études présentées parfois comme des statistiques et parfois davantage comme des essais comparatifs. Voici quelques résultats en ne retenant, dans chaque étude, que les quatre meilleurs.
- Une étude donne : Asp.net, Django, Laravel, Ruby on Rail.
- Une autre étude donne : Django, Laravel, Ruby on Rail, ExpressJS.
- Une troisième étude donne : Django, ExpressJS, Flask, Laravel.
- Une quatrième étude donne : Meteor, ExpressJS, NextJS, Laravel.
- Une cinquième étude donne : ExpressJS, Django, Rails, Laravel.
- Une sixième étude donne : Laravel, Django, Flask, ExpressJS.
On remarque que Laravel est le seul framework qui revient à chaque fois mais que deux autres framewoks sont aussi appréciés : Django et ExpressJS. On remarque aussi qu’il est suspect que se trouvent placés en tête de liste dans certaines études des frameworks comme Asp.net ou Meteor. Il s’agit probablement d’une publicité masquée.
A cette étape de nos investigations nous aurions pu choisir Django ou ExpressJS mais nous avons vu aussi qu’il faut, à partir du framework de back-end, constituer un ensemble en ajoutant des « kits » supplémentaires et des frameworks de front-end sans oublier qu’il faudra un « stater-kit ». Quand nous avons essayé de constituer ainsi des ensembles cohérents, il est vite apparu que c’est en partant de Laravel que nous arrivions le plus facilement au meilleur « package ». En fin de compte, c’est le classement qui place Laravel en tête qui nous semble le plus fiable. Nous le reproduisons ci-dessous.
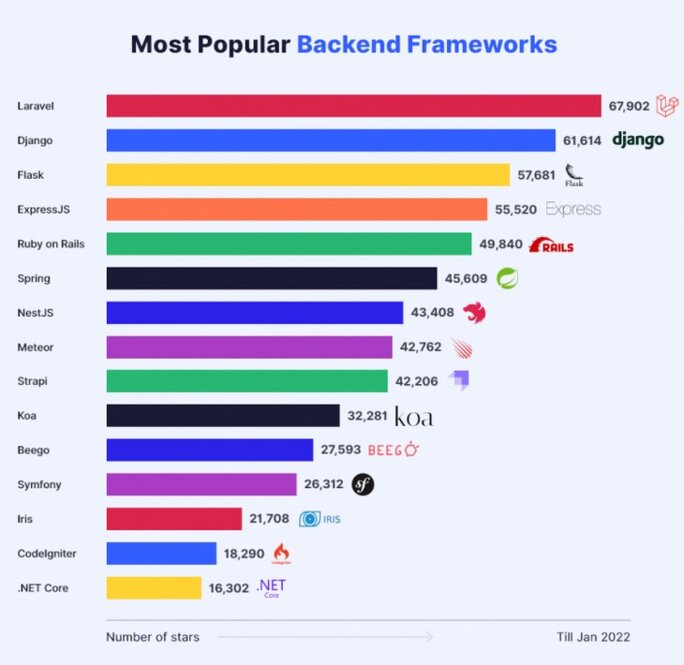
Agrandissement : Illustration 4
Les réserves que nous avons émises sur deux études sont alors confirmées et la liste des autres frameworks bien côtés est cohérente avec ce que nous avions vu (Django, Flask, ExpressJS et Ruby on Rails).
Nos choix
En conséquence de toutes nos investigations et compte-tenu de l’ensemble de nos contraintes et de nos critères de choix par rapport à l’offre actuelle nous avons arrêté les décisions suivantes.
- Laravel sera notre principal framework auquel nous associerons deux kits principaux.
- Jetstream sera notre « starter kit ». Il sert à gérer les inscriptions, logins, authentifications, connexions, confirmation et réinitialisation du mot de passe…
- LiveWire sera le principal kit qui fonctionnera avec Laravel. Remarquons qu’avec Jetstream le choix de LiveWire s’impose. La seule alternative possible serait Inertia.
- Tailwind s’impose pour le front-end. Il est en effet utilisé dans Laravel et Jetstream pour présenter les diverses vues comme la page d’accueil (welcome.php). Nous suivons le choix des concepteurs de l’ensemble de nos frameworks.
- Alpinejs est un framework JavaScript minimaliste et facile à utiliser qui se marie bien avec Laravel. Il est plus simple que Vue.js qui lui fait concurrence et il est suffisant quand il est associé aux autres outils sélectionnés ici.
- Nous utiliserons Filament pour faire les interfaces d’administration (tableaux de bord ou « dashboard ») réservées aux administrateurs.
- Nous testerons divers éditeurs avant d'en choisir un.
La cohérence et la complémentarité de ces divers composants est reconnue par de nombreux développeurs web. Cela vaut notamment pour les 4 outils : Tallwind, AlpineJS, Laravel et Livewire qui sont souvent désignés avec l’acronyme TALL. On parle alors de la Tall Stack. L’ensemble permet évidemment de faire du « full-Stack ».
L’offre évolue en permanence. Nos choix n’auraient pas été les mêmes quelques mois auparavant. Maintenant Tailwind s’impose face à Bootstrap et Jetstream s’impose face à Breeze. Nous ne pouvons pas donner ici les descriptions de ces différents outils pour justifier nos choix qui, répétons-le, auraient été différents l’an passé. Nous pourrons éventuellement répondre à toutes les questions qui nous parviendront à ce sujet.
L’ensemble choisi inclut les composants suivants :
- Composer est le premier composant écrit avec PHP. Il permet de mettre en place tous les autres composants : kits et frameworks. C’est un outil de gestion de dépendances via la console. En gros il permet d'ajouter ou de retirer facilement, via un fichier composer.json des composants de l’application sur laquelle on travaille.
- Artisan est un programme écrit en PHP. Il fournit un serveur de développement local qui est lancé dès que le projet est initialisé. Dès lors l’application est accessible dans n’importe quel navigateur web à l’adresse http://localhost:8000. C’est aussi Artisan qui fait les « migrations » c’est-à-dire les interventions sur la base de données à partir du codage en PHP. Il créera et modifiera les tables de la base de données. Artisan crée aussi les Modèles qui font l’interfaçage permettant d’agir sur les tables de la base de données. Il crée aussi les Contrôleurs qui traitent les demandes et renvoient les réponses (Architecture MVC).
- Alpinejs est un environnement d'exécution JavaScript open source et multi-plateforme. Il est parfois considéré comme un framework. C’est plutôt un environnement d’exécution pour des programmes écrits en Javascript. Il permet donc d’écrire des applications en Javascript du côté du serveur alors qu’auparavant le Javascript était seulement exécuté par les navigateurs du côté des clients. De plus, 13 bibliothèques permettent de réutiliser du code sans avoir à le réécrire. Node.js est intégré à Laravel.
- Laravel Blade est le moteur de modèles par défaut du framework Laravel. Il vous permet d'utiliser des variables, des boucles, des instructions conditionnelles et d'autres fonctionnalités PHP directement dans le code HTML.
- Eloquent est l’ORM (Object-Relational Mapping) de Laravel c’est-à-dire un logiciel permettant la conversion des données relationnelles d’une base de données en objets afin de pouvoir les manipuler dans une application avec une Programmation Orientée Objet. Il permet le passage de l’un à l’autre (des données relationnelles à la programmation orientée objet). Il encapsule les attributs d’une table ou d’une vue dans une Class. Les lignes de la table deviennent donc des « tuple » côté PHP. Nous n’utiliserons donc jamais directement de requêtes SQL pour accéder à la base de données. C’est Eloquent qui s’en charge. Il permet d'utiliser de simples fonctions PHP à la place des requêtes SQL. En plus, Eloquent permet de fabriquer des données de test pour simuler le fonctionnement réel de l’application dès la phase de développement. Il est en effet pour cela nécessaire de disposer de données en grand nombre si on veut par exemple simuler un système de pagination et il serait fastidieux de rentrer toutes ces données « à la main ».
- Vite est un empaqueteur (bundlers) qui permet de regrouper les fichiers Javascript et CSS, de compresser les images, de lancer un « transpiler »…
Notre choix primordial c’est porté sur Laravel qui a été conçu en regroupant le meilleur des bibliothèques existantes. Cela a parfois été reproché à Taylor Otwel qui est le principal concepteur. De nombreux composants originaux ont ensuite été ajoutés et l’ensemble a été mis en cohérence. Je n’ai signalé ci-dessus que les principaux modules. Nous trouvons aussi dans Laravel :
- un système de routage (RESTFul et ressources),
- un créateur de requêtes SQL et un ORM,
- un moteur de template,
- un système d’authentification pour les connexions,
- un système de validation,
- un système de pagination,
- un système de migration pour les bases de données,
- un système d’envoi d’emails,
- un système de cache,
- un système de gestion des événements,
- un système d’autorisations,
- une gestion des sessions,
- un système de localisation,
- un système de notifications…
Laravel s’est établi en quelques années au sommet de l’usage des frameworks PHP. Il est encore concurrencé par Django et ExpressJS mais nous le choisissons parce qu’il nous semble le plus complet en offrant avec ses différents kits un ensemble cohérent relativement facile à utiliser. Il faut cependant y consacrer un temps d’apprentissage important mais qui sera rentable à l’usage. Nos choix impliquent que nous n’utiliserons aucun autre outil que ceux que nous avons cités. Dès lors, nous savons sur quels outils il faut nous focaliser.
Pour compléter ces choix, il reste à préciser ce que contient notre environnement de développement. Nous utilisons Laragon sous Windows. Nous avons d’ailleurs supprimé Wamp que nous utilisions auparavant. Laragon propose divers SGBD mais nous nous en tenons à MySQL. Il contient évidemment un serveur local (Apache), l’interpréteur PHP et divers outils dont l’indispensable phpMyAdmin mais aussi Composer, Nodejs, Putty, Memcached, git…. Il est surtout très facile à utiliser. Nous utilisons Visual Studio Code comme principal éditeur mais aussi notepad++ qui nous sert principalement à lire du code venant d’autres applications pour faire des copier-coller entre les deux éditeurs. Enfin, FileZilla permet de transmettre l’application par FTP sur le serveur externe lors du déploiement et Putty permet d’intervenir à distance sur ce serveur. Nous ajoutons des fonctionnalités à l’éditeur Visual Studio Code avec quelques plugins comme PHP Intelephense, Tailwind CSS IntelliSense, Laravel Blade Snippets, Laravel Extension Pack, Laravel goto view, Laravel extra intellisense, Laravel Blade Spacer.

Agrandissement : Illustration 5

Spécification
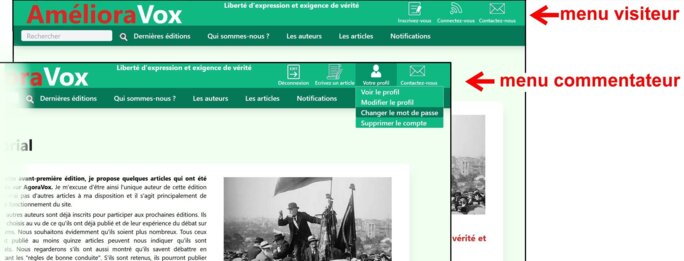
Il faut spécifier le plus précisément possible ce que doit faire le site de « journalisme lobre ». Nous allons voir maintenant plus concrètement comment nous allons traiter la principale difficulté du projet : la multiplicité des catégories de membres qui n'ont pas les mêmes attributions avec la gestion des changements de catégories.
Dans la base de données, une « colonne » avec l’attribut « statut » précisera quel est le statut de chaque utilisateur et dans l’interface utilisateur apparaitront des attributions différentes en fonction de ce statut. Cela se verra principalement (mais pas uniquement) dans les items proposés dans le « menu » du « header » et dans la barre de navigation. Ces deux parties forment l’entête de chaque page HTML affichée sur l’écran. En d’autres termes nous proposons une entête dynamique puisqu’elle change en fonction du statut de l’utilisateur.
Nous avons donc des entêtes pour chaque statut d’utilisateur. Voici plus précisément nos propositions de divers statuts. Nous indiquons entre parenthèse le terme anglais qui sera utilisé dans le code de l’application :
- Les simples visiteurs (visitor). Ils ne sont pas connectés et ne peuvent donc que visiter Le site pour regarder les articles qui sont proposés avec les différents outils permettant de les rechercher. Les visiteurs ne sont pas connectés soit parce qu’ils l’ont choisi soit parce qu’ils sont sanctionnés : ils subissent alors ce que nous appellons un « blocage global ».
- Les commentateurs (commentator). Ils sont connectés. Ils se sont donc inscrits sur le site. Après une inscription valide, on a dans la table « users » l’initialisation du « statut » avec la valeur « commentateur ». Le booléen « is_forbidden » (est_bloqué) est initialisé à « false ». Les commentateurs disposent d’un « login ». Ils ont la possibilité de commenter les articles et de proposer un article. Ils peuvent recevoir des notifications lorsqu’ils sont sanctionnés par la suppression d’un commentaire ou par un « blocage » effectué par l’un des auteurs. Je rappelle toutefois que les auteurs qui prennent une sanction ne sont pas tenus d’envoyer une telle notification. Quand un commentateur propose un article, il change de statut. On a alors : Si statut = commentateur alors statut <- candidat_auteur
- Les candidats-auteurs (author-candidate). Ils ont déjà proposé un ou plusieurs articles mais aucun n’a été accepté. Ils sont donc susceptibles d’avoir reçu des notifications au sujet des articles proposés. Ce sont des appréciations envoyées par des « sélectionneurs » avec éventuellement des propositions de modifications à apporter. Ils peuvent donc recevoir des notifications de deux catégories différentes. Ce seront soit des notifications d’une sanction soit des appréciations portées sur les articles qu’ils ont proposés. Ils ont par ailleurs la possibilité de gérer les articles qu’ils ont proposés et qui sont en cours de modération. Ils peuvent les modifier ou les supprimer. Quand un article d’un candidat-auteur est retenu et publié, le candidat-auteur change de statut. Il devient auteur. On a deux modifications dans la table « users » pour l’instance le concernant : Si statut = candidat_auteur alors statut <- auteur ; Date_premier_article <- date_du_jour ;
- Les auteurs (author). Ils ont publié au moins un article. Ils ont assuré la modération pour l’article ou les articles qu’ils ont publié. Ils ont donc eu la possibilité de supprimer des commentaires et de bloquer des commentateurs pour les articles qu’ils ont publiés. A l’occasion, ils ont pu envoyer des notifications. Ils ont trois items supplémentaires dans le menu-déroulant de la modération (« voir tous mes articles », « notifications envoyées » et « gestion des blocages »). « Voir tous mes articles » leur donne accès à tous les articles qu’ils ont proposés qu’ils aient été ou non publiés. La gestion des blocages consiste uniquement à supprimer des blocages qu’ils ont mis en place. Quand un article d’un auteur est publié il faut regarder si le nombre d’articles publiés de l’auteur a atteint le score lui permettant de devenir sélectionneur. On a alors deux modifications dans la table « users » pour l’instance le concernant : Si (statut = auteur et NbrArticlesPublies = seuil) alors statut <- selectionneur ; DateNominationSélectionneur <- date du jour ;
- Les sélectionneurs (coach) ont donc publié un nombre d’articles égal ou supérieur à un certain seuil lequel est susceptible d’évoluer. Actuellement le seuil est de quinze articles. Leur menu-déroulant concernant la modération contient 6 items : voir tous mes articles, notifications reçues, notification envoyées, gestion des blocages, articles en cours de modération, réunions du comité éditorial. L’item « articles en cours de modération » permet de multiples actions. Il leur donne accès à leurs propres articles en cours de modération pour qu’ils puissent les modifier ou les supprimer. Ils peuvent indiquer qu’ils sont favorables à la publication de certains articles. Ils peuvent envoyer des appréciations sur certains articles proposés indépendamment du fait qu’ils se soient prononcés ou non en faveur de leur publication. L’item « réunions du comité éditorial » leur donne les infos sur les prochaines réunions afin qu’ils puissent y participer et des indications sur les décisions prises lors des précédentes réunions.
- Les membres du CE (Editorial-Board member) sont ceux qui participent aux réunions de ce comité lesquelles se font le plus souvent en visio-conférences. Les critères permettant de devenir membre pourront évoluer. Actuellement, il suffit d’avoir participé à une réunion du CE. Il sera probablement tenu compte du nombre de participations aux réunions du CE mais aussi de la participation à la modération du site. Il sera tenu compte en particullier du nombre et de la qualité des appréciations envoyées. Actuellement, le fait d’être membre du comité éditorial ne confère aucun droit supplémentaire par rapport aux sélectionneurs sur le site web. Leurs attributions supplémentaires viennent du fait qu'ils participent aux décisions du CE. Les administrateurs seront probablement recrutés parmi les membres du CE.
- Les administrateurs (admin). Un administrateur devra se loguer avec une procédure particulière, séparée du login classique des utilisateurs. La personne physique qui a un statut d’administrateur peut donc être aussi un utilisateur avec n’importe quel statut. Les administrateurs sont chargés d'appliquer sur le site web les décisions prises en réunion du Comité Editorial. En particulier, ils mettent en œuvre les choix fait pour une édition. Ils ont accès à la procédure d’édition sur l’un des panneaux d’administration. Ils sont aussi chargés d’appliquer les sanctions décidées en réunion du Comité Editorial et ils peuvent en plus prendre des initiatives à ce sujet dans l’urgence (falsifications, diffamations, non-respect des droits d’auteurs). Ces sanctions sont la suppression d’un article, le blocage-global d’un « acteur » pour une durée déterminée, la suppression du compte d’un auteur (suppression de tous ses articles, de tous ses commentaires et de tous les commentaires qui étaient liés à ses articles ainsi que les réponses aux commentaires…). Précisons qu’avec un blocage-global, l’utilisateur ne peut plus se loguer. Il redevient simple visiteur. Les administrateurs peuvent aussi supprimer des commentaires et ils gèrent les catégories et les étiquettes d’articles. Ils peuvent envoyer des notifications à tout moment si cela leur semble utile.
- Les super-administrateurs (super-admin). Ce sont ceux qui sont à l’initiative de la création du site et en assurent la conception et la réalisation. Ils en assurent aussi la maintenance avec d’éventuelles modifications et mises à jour. Ils doivent avoir pour cela la compétence requise. Ils ont libre accès à la totalité de la base de données et du site. Ils possèdent les codes nécessaires à la connexion chez le fournisseur d’accès. Ils sont les responsables du site au regard de la loi. Ils sont d’ailleurs les propriétaires du site. Pour l’instant, je suis l’unique « super-administrateur » et il me revient de choisir les administrateurs.
Voici ce que pourrait être l’interface utilisateur qui permet la mise en œuvre de ce que nous venons de décrire. J’en ai réalisé la maquette.
<img data-asset="<img data-asset="<img data-asset="
Agrandissement : Illustration 6
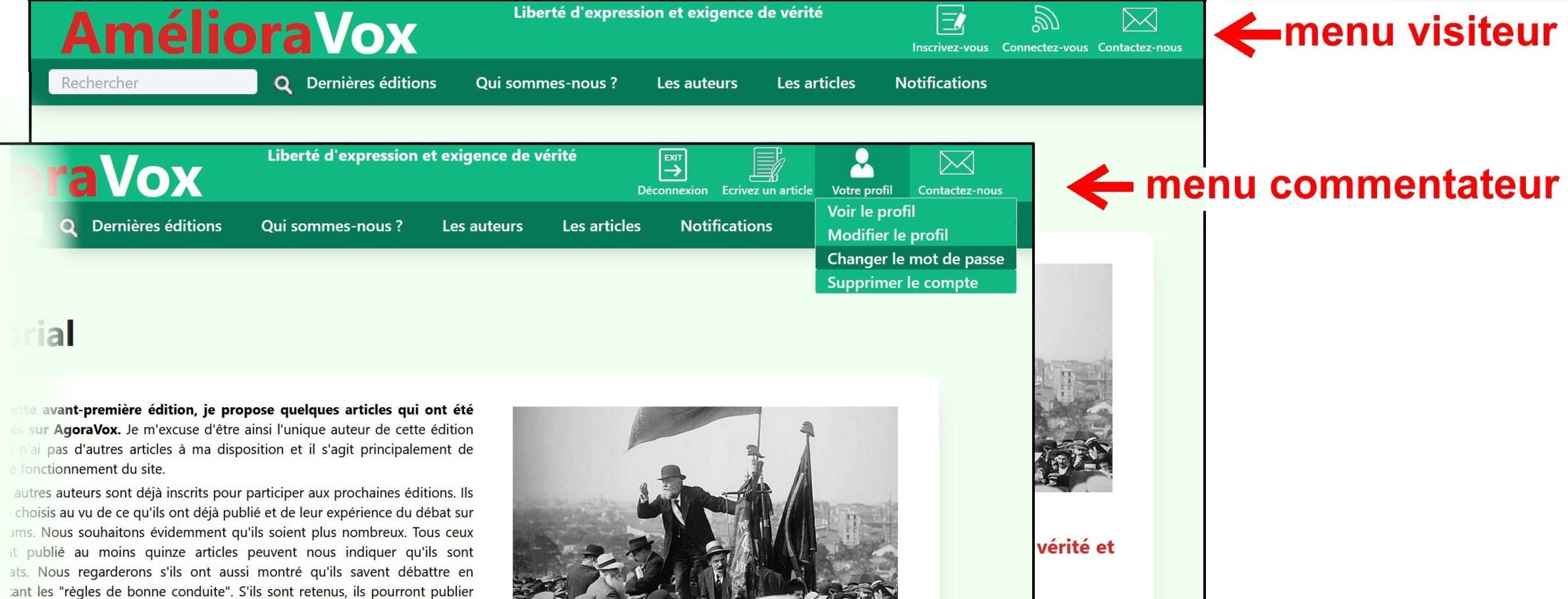
Nous avons fait le choix d’avoir des termes en anglais dans les tables de la base de données.
Agrandissement : Illustration 7
La relation « a plus de permissions que » est une relation d’ordre entre ces classes d’utilisateurs.
Ajoutons qu’un utilisateur logué peut :
- Etre libre de toute contrainte de blocage.
- Subir un blocage-global pour une période déterminée. L’acteur est averti en essayant de se loguer qu’il ne peut que consulter le site comme un simple visiteur pendant la période de blocage. Quand le blocage s’achève il récupère son ancien statut. On aura donc un booléen « Est_bloque » et une variable « Statut » dans la table « users ».
- Etre bloqué (impossibilité de commenter) pour les articles de certains auteurs. Dans ce cas l’article s’affiche sans l’éditeur permettant de rédiger un commentaire. Celui-ci est remplacé par le message : « Vous ne pouvez plus commenter les articles de cet auteur ».
La base de données
Il faut aussi spécifier ce que sera la base de données. Je suis suffisamment avancé dans cette spécification pour qu’il soit possible de passer dès maintenant à l’implantation. Voici le schéma prévisionnel de la base de données.
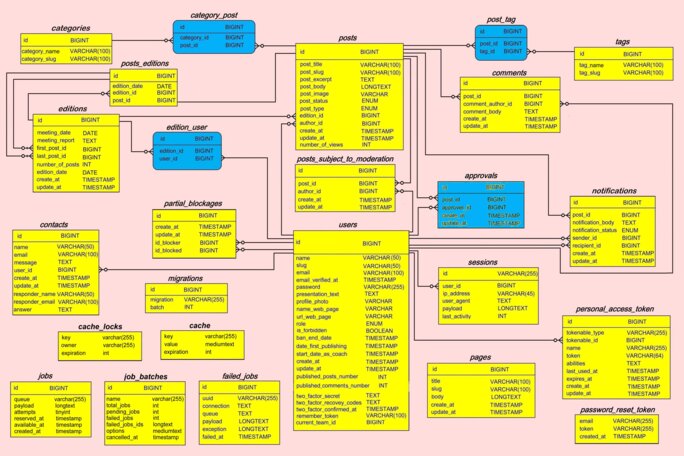
Agrandissement : Illustration 8

J’ai commencé par essayer de suivre, pour la conception de la base de données, la méthode qui part d’une analyse conceptuelle pour aboutir à la conception physique de la base de données. Finalement, je suis passé directement à la conception physique en m’appuyant sur l’expérience déjà acquise ailleurs dans la conception des sites de blog. Cela nous donne les 9 tables suivantes : posts, users, comments, categories, category_post, tags, post_tag, contacts et pages. Par ailleurs, l’installation de Jetstream génère automatiquement la mise en place des 6 tables suivantes : users, sessions, personal_access_token, failed_jobs, migrations, password_reset_taken. Cela fait un total de 14 tables (La table users est en effet citée deux fois).
J’ai donc ajouté seulement 7 tables pour passer d’un simple blog à notre site de « journalisme libre ». En voici la liste : editions, posts_editions, edition_user, posts_subject_to_moderation, approvals, notifications et partial_blockages.
Je vais passer en revue chacune de ces tables. En suivant cet ordre :
- Les tables d’un site de blog ordinaire.
- Les tables implantées par Jetstream.
- Les tables supplémentaires pour un site de « journalisme libre ».
Les choix sur la structure de la base de données dépendent évidemment de ce que fera l’application et le choix entre diverses options reste ouvert. Je montrerai aussi que la structure des données dépend parfois du traitement. Je vais donc passser en revue les différentes parties de cette base de données.
Les tables « users », « posts » et « comments ».
Les principales tables de la base de données contiennent les utilisateurs, les articles et les commentaires.
Les tables « categories », « tags », « category_post », « post_tag »
Des systèmes plus ou moins complexes de classification des articles peuvent être mis en place avec des catégories et des étiquettes :
- Une catégorie par article (une seule table).
- Une catégorie et une étiquette par article (deux tables).
- Une catégorie et plusieurs étiquettes par articles (trois tables).
- Plusieurs catégories et plusieurs étiquettes par articles (quatre tables).
Nous choisissons la solution la plus complète avec plusieurs catégories et plusieurs étiquettes.
Avec les tables categories et tags, il faut ajouter deux autres tables puisqu’on a des relations « many to many ».
- category_post (Un article peut avoir plusieurs catégories. Une catégorie peut être affectée à plusieurs articles).
- post_tag (Un article peut avoir plusieurs étiquettes. Une étiquette peut être affectée à plusieurs categories).
La table migrations sert seulement d’intendance pour les migrations et vous ne devez pas y toucher.
La table password_reset_tokens va nous servir pour la réinitialisation des mots de passe.
La base de données du site de journalisme libre contiendra deux entités supplémentaires (notifications et éditions). Nous aurons donc en tout 7 entités.
- Users (utilisateurs)
- Posts (articles)
- Comments (commentaires)
- Categories
- Tags (étiquettes)
- Editing (éditions)
- Notice (Notifications)
Pour les notifications, il faudra un champ pour indiquer le type de notification. On peut en effet avoir :
- Des notifications envoyées par un auteur lors de la suppression d’un commentaire.
- Des notifications envoyées par un auteur effectuant un blocage pour un commentateur qui n’interviendra plus.
- Des notifications envoyées par un « sélectionneur » pour transmettre ses appréciations sur un article proposé en modération.
- Des notifications envoyées par un administrateur lors d’un blocage global en sachant qu’elles ne seront lues que lorsque l’utilisateur concerné pourra à nouveau se connecter.
- Autres notifications envoyées par des administrateurs.
Voici donc les libellés en français des catégories de notifications. Nous trouverons les traductions en anglais :
- suppression_commentaire
- blocage_auteur
- appreciation_article
- blocage_global
- autre
La table sur « editing » contiendra des informations sur l’édition proprement dite puisqu’elle sert à indiquer la liste des articles publiés lors d’une édition mais elle contient aussi des informations sur la réunion du Comité Editorial qui a pris les décisions. En particulier, on pourra retrouver la liste des « sélectionneurs » qui ont participé à la réunion (les membres du Comité Editorial). On aura alors à nouveau une relation « many to many » qui nécessitera une table pivot supplémentaire. En effet, un « sélectionneur » peut participer à plusieurs réunions du Comité éditorial et une réunion du Comité Editorial rassemble plusieurs sélectionneurs.
Il faudra évidemment compléter cette analyse en donnant la liste complète de chaque champ pour chaque table avec les types de données. Il faudra donc aussi refaire le schéma complet de la base de données en intégrant les 3 nouvelles tables (2 pour les entités et la table pivot). Et il reste encore bien d’autres points à préciser avant de passer à la réalisation.
Je m’en tiens là, pour l’instant, sur la spécification du site web de journalisme libre.
Le financement du projet
Le principe adopté pour l'instant est simple : ne faire aucune dépense.
Je ne crois pas que je pourrais continuer ainsi. Je me permets donc de lancer dès maintenant un appel aux dons. Contactez-moi pour cela à mon adresse email : jeandugenet@gmail.com. Vous constaterez que sur ces questions, comme sur d'autres, je reprends à mon compte les idées qui prévalaient au moment où AgoraVox a été inventé. Je me tourne donc vers ceux qui veulent défendre nos principes :
LIBERTE D'EXPRESSION ET EXIGENCE DE VERITE.

Agrandissement : Illustration 9
