



thetransmitter.org Traduction de "Crowdsourcing to curb aggression in autism: Q&A with Matthew Goodwin" Par Daisy Yuhas
2 mai 2024
Le crowdsourcing* pour freiner l'agressivité dans l'autisme : Questions-réponses avec Matthew Goodwin
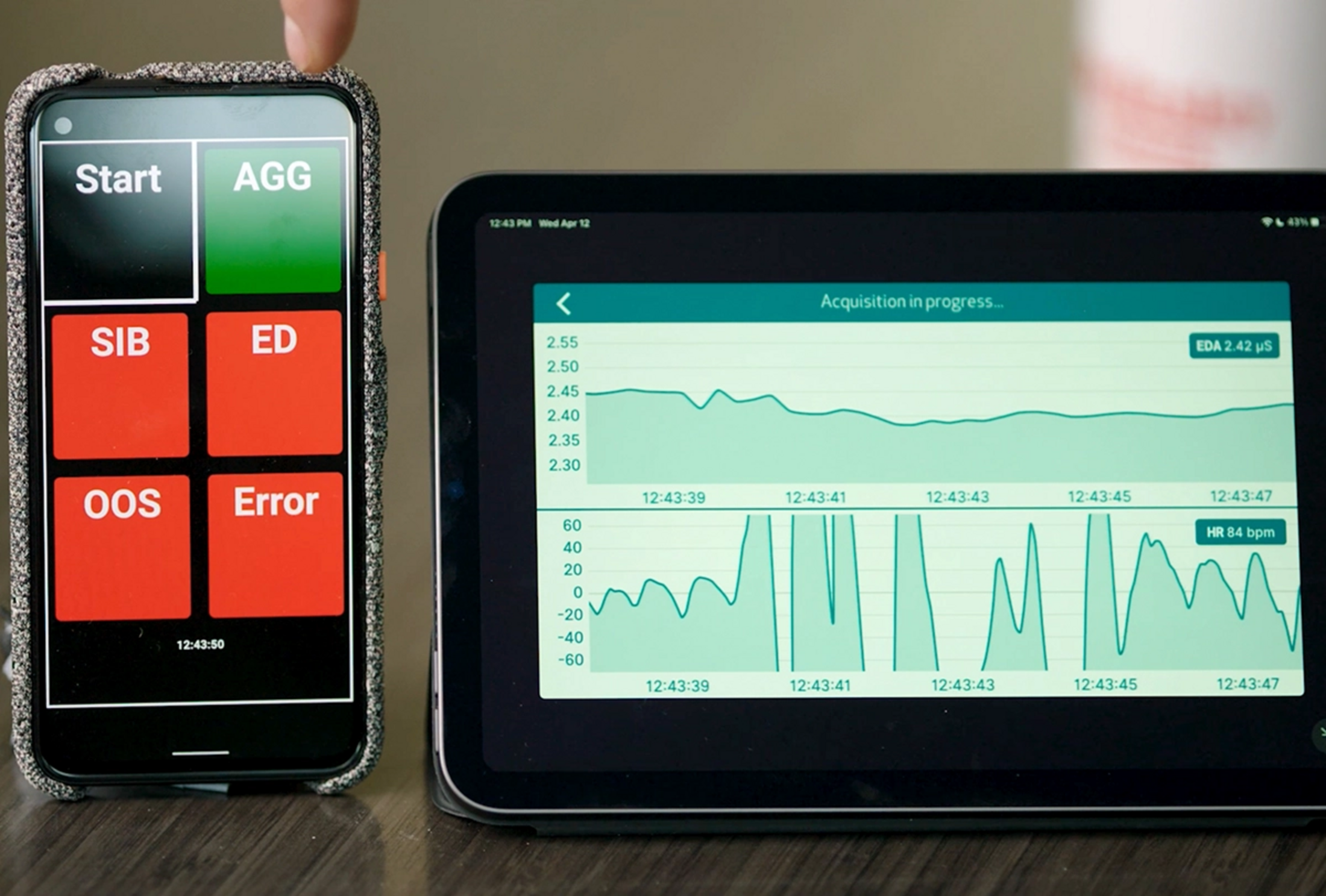
Selon une étude publiée en décembre dans JAMA Network Open, des biocapteurs portatifs peuvent prévoir un comportement agressif chez les personnes autistes trois minutes avant un accès de colère. Selon le chercheur principal Matthew Goodwin, professeur interdisciplinaire à la Northeastern University, cette fenêtre est suffisante pour faire quelque chose.
En l'espace de trois minutes, par exemple, les soignants pourraient intervenir pour calmer un enfant atteint d'autisme profond avant qu'il n'adopte un comportement dangereux pour lui-même ou pour les autres.
Goodwin et ses collègues développent cette technologie depuis plusieurs années, mais leur dernier article reproduit et développe de manière significative les résultats de la preuve de concept qu'ils ont publiés en 2019, en ajoutant davantage de participants, de sites d'étude et de comportements prédits.
Pour faire progresser l'approche, l'équipe affine le logiciel et les algorithmes qui prennent en charge les notifications téléphoniques en temps réel des comportements agressifs imminents et conçoit des études pour explorer comment les gens bénéficient de ces alertes. Elle collabore également avec le Marcus Autism Center pour élaborer des plans de gestion du comportement et des stratégies d'intervention ciblées afin de compléter ces alertes précoces.
Selon M. Goodwin, de nombreuses questions fondamentales doivent encore être résolues avant que ces outils puissent être mis à la disposition des familles. Pour y contribuer, lui et ses collègues partagent les données de leur étude sur la base SFARI, y compris l'activité électrodermale, le pouls du volume sanguin et les annotations comportementales de 69 participants pendant 497 heures d'observation. (La Fondation Simons, l'organisation mère de The Transmitter, finance la base SFARI). L'ensemble des données a été mis en ligne le 16 avril 2024.
"De nombreuses personnes sont intéressées [par la recherche] et un sous-ensemble d'entre elles ont probablement des connaissances qu'elles peuvent mettre à profit", explique-t-il. "Désormais, grâce à l'ensemble de données de la base SFARI, ils peuvent réellement travailler avec."

Agrandissement : Illustration 1
The Transmitter s'est entretenu avec M. Goodwin au sujet de cette décision et de ses espoirs de collaboration avec d'autres experts.
L'entretien a été édité pour des raisons de longueur et de clarté.
The Transmitter : Pourquoi partager l'ensemble des données de cette dernière étude ?
Matthew Goodwin : Pour de multiples raisons. La première est la transparence scientifique. On accorde beaucoup d'attention - à juste titre - à la recherche qui fait appel à l'apprentissage automatique. On craint qu'il s'agisse de boîtes noires, que nous leur accordions trop de confiance et que seuls certains groupes puissent obtenir certains résultats.
J'aimerais que les gens examinent nos méthodes et nos données. Dans l'article du JAMA, nous avons donc publié un supplément qui détaille, étape par étape, tout ce qu'il faut savoir pour comprendre comment nous avons segmenté les données, prétraité les données, dérivé nos caractéristiques, [et cetera]. Je veux que les gens sachent exactement ce que nous avons fait.
Ensuite, une fois qu'ils savent, je veux mettre l'accent sur la reproductibilité. Je veux voir si d'autres personnes obtiennent les mêmes résultats que nous et si nous ne sommes pas une simple licorne.
Le grand défi que j'aimerais lancer à cette communauté, si je le pouvais, serait d'augmenter notre temps de prédiction dans l'avenir avec un niveau plus élevé de validité prédictive et une valeur prédictive positive accrue. Je voulais vraiment que l'analyse des données soit confiée à d'autres scientifiques. Je ne veux pas que mon équipe soit la seule à travailler avec ces données. Le problème est trop important et trop complexe.
TT : Avec des données liées à plus de 6 000 épisodes comportementaux de 69 jeunes autistes, il y a beaucoup à étudier. Que pensez-vous que l'on puisse apprendre ?
MG : De nombreuses questions peuvent être posées. Par exemple, existe-t-il d'autres caractéristiques que l'on pourrait intégrer manuellement dans les modèles et qui permettraient d'augmenter la durée de la prédiction ? Ou d'accroître la précision ?
Et il y a de nombreuses questions qui vont au-delà de la prédiction. Les quatre sites participants font partie de l'Autism Inpatient Collection, de sorte que les participants à notre étude ont tous des identifiants uniques globaux SFARI. Si quelqu'un a la permission d'accéder à cet ensemble de données, il peut alors poser des questions sur les différences en fonction de l'âge, du sexe et des aptitudes verbales, par exemple.
Des prises de sang ont également été effectuées pour les participants [et ces données seront disponibles dans les mois à venir sur la base SFARI], ce qui signifie qu'il est également possible d'explorer différents profils génétiques. Les liens entre les différences génétiques sous-jacentes et les manifestations comportementales suscitent beaucoup d'intérêt.
TT : En d'autres termes, les chercheurs en autisme, les épidémiologistes et les généticiens pourraient trouver quelque chose d'intéressant ici. Y a-t-il d'autres experts qui, vous l'espérez, exploreront cet ensemble de données ?
MG : Il y a des gens qui ont des connaissances que je n'ai pas - en mathématiques appliquées, en physique et en apprentissage automatique - et qui pourraient apporter de nouvelles idées. Pour l'essentiel, nous avons fourni des phénomènes temporels. Certains économistes et ingénieurs modélisent le décollage et l'atterrissage des avions, les effets de la circulation et le marché boursier à l'aide de modèles mathématiques très sophistiqués. Ces personnes ne pensent pas à l'autisme et à l'agressivité, mais leurs méthodes mathématiques sont bien adaptées à ce défi.
Ils peuvent considérer les données de notre étude comme une série temporelle multivariée et modéliser le temps écoulé jusqu'à l'événement. Il n'est pas nécessaire de connaître quoi que ce soit sur l'autisme, la physiologie ou un comportement agressif pour faire cela.
J'aimerais ouvrir une conversation parce que je ne sais pas qui sont ces personnes aujourd'hui. Je ne sais pas où elles se trouvent. Je ne sais pas comment les trouver. Je ne sais pas comment les inciter à travailler avec moi. Cela pourrait être un moyen d'y parvenir.
TT : Vous voulez donc trouver de nouveaux partenaires ?
MG : Je l'espère. J'aimerais vraiment créer une relation avec les personnes qui accèdent aux données et les publient. Nous pourrions apprendre des succès et des échecs des uns et des autres.
Si quelqu'un me tend la main et me dit : "Voici ce que j'ai l'intention de faire", je peux aider à coordonner, à trier et à mettre en relation les personnes afin qu'elles ne fassent pas double emploi. S'ils obtiennent des résultats, mais que, pour une raison ou une autre, ils ne les publient pas, nous ne sommes pas dans l'ignorance du fait que quelqu'un a déjà essayé quelque chose et que cela n'a pas fonctionné.
Je ne demande pas d'être inclus en tant que co-auteur dans le travail de tous les autres, mais j'aimerais qu'ils lisent et citent cet article et reconnaissent que c'est de là qu'ils ont tiré les données, afin que moi-même et d'autres puissions assimiler ou fédérer à travers ce groupe de personnes réparties.
TT : Que doivent garder à l'esprit les chercheurs lorsqu'ils examinent cet ensemble de données ?
MG : Il se trouve dans la base SFARI, de sorte que seuls les utilisateurs enregistrés peuvent y accéder. Ces utilisateurs doivent être certifiés en tant que sujets humains et comprendre qu'il s'agit d'une population protégée. Comme il s'agit de la base SFARI, je sais également qui accède à la base de données et à quel moment. Les données sont également sécurisées et privées afin qu'elles ne soient pas utilisées à d'autres fins que la recherche.
TT : Quelle est la vision finale de tout ce crowdsourcing ?
MG : L'objectif net serait d'apporter plus rapidement des solutions aux familles. Ces familles ont besoin d'aide tout de suite.
Quels que soient les talents que les gens ont à apporter pour faire avancer l'état de l'art, nous voulons les accueillir. Les succès et les échecs sont tout aussi importants - et tout aussi appréciés - que les façons dont les gens mettent leurs talents au service de ce problème de société.
* Le crowdsourcing consiste littéralement à externaliser (to outsource) une activité vers la foule (crowd) c’est-à-dire vers un grand nombre d’acteurs anonymes (à priori) . Bien que le phénomène soit ancien (par exemple, les chasseurs de prime), son essor est fortement lié au développement des nouvelles technologies de l’information et de la communication et, plus particulièrement, du Web 2.0 qui facilite la mise en relation d’un grand nombre d’acteurs dispersés (Cardon, 2006). Le crowdsourcing est une forme d’externalisation voire de collaboration possible avec des individus à l’extérieur de l’entreprise. Crowdsourcing : définition, enjeux, typologieThierry Burger-Helmchen, Julien Pénin