



Je ne suis ni voyante extra-lucide ni épidémiologiste, mais j’ai quelques vagues connaissances en statistique et en probabilité, et je me suis posé comme tout le monde certaines questions sur l’évolution de cette crise pandémique qui nous retient fermement à domicile depuis une quinzaine de jours, et dont on n’arrête pas de nous rebattre les oreilles sur toutes les chaînes, réseaux et longueurs d’onde. Aussi, après avoir étudié quelques séries de données publiques, mais assez difficiles d’accès, je me suis convaincu que l’on pouvait tenir un discours sensé et rationnel sur les conditions de sortie de cette situation, pourvu que l’on analyse avec méthode les chiffres que l’on nous propose et que l’on fasse des hypothèses crédibles sur le comportement de ce sacré coronavirus.
En effet, le « modèle théorique » (les anglo-saxons diraient le « pattern ») que suit l’évolution de l’épidémie se reproduit constamment d’un pays à l’autre, et même d’une région à l’autre comme on le voit dans le cas de la France où la contagion a d’abord gagné l’Est et le Nord du pays avant de toucher l’Ile de France et de poursuivre vers l’Ouest et le Sud. Il semble donc raisonnable de penser que le virus après avoir atteint la réalisation de ses pleines capacités va graduellement s’étioler et finalement disparaître. La question qui se pose alors est de se demander quand cette issue de la crise va se produire. Ce n’est pas si simple parce qu’il y a de nombreuses inconnues, à commencer par la connaissance précise du virus qu’on ne peut assimiler à une simple grippe saisonnière. Il n’en a apparemment ni les caractéristiques pathogènes, ni le même degré de contagiosité, ni le comportement en termes de cycle de vie et de mutation aléatoire. Je laisse au corps médical le soin de répondre à ces questions, qu’il ne manquera pas d’élucider dans les années qui viennent, puisqu’il s’agit d’une des plus grandes pandémies que notre planète aura jamais connues.
Deux hypothèses de fond
Toutefois, en l’absence de diagnostic assuré, il me semble possible de supposer que le comportement du virus obéit à deux types de déterminants :
- Une dynamique interne propre, que l’on retrouve dans toutes les épidémies historiques, à des degrés variables, et qui se traduit par un cycle de vie assez spécifique à l’agent pathogène. Ce dernier comporte évidemment un lent début, puis une montée de plus en plus rapide vers un pic où il peut culminer quelque temps, et enfin une chute qui peut elle-aussi s’étaler dans le temps. Je fais l’hypothèse, raisonnable, qu’en dehors de toute mutation, qui en altérerait le cycle, le même virus doit avoir par nature un comportement similaire au sein d’une même vague épidémique. En d’autres termes, la contagion devrait avoir peu ou prou les mêmes caractéristiques de durée et d’intensité dans tous les pays ou régions qu’elle touche, toutes choses égales par ailleurs. C’est cette hypothèse de base que j’étudie ici.
- Des conditions particulières, propres à la société et à sa charpente locale où sévit le virus, peuvent modifier dans une certaine mesure les caractéristiques précédentes, en fonction de la structure par âge, de la morbidité ou des conditions de vie, etc. C’est bien évidemment le cas dans notre pays où les régions densément peuplées, et a fortiori les grandes métropoles où les contacts fréquents entre les gens favorisent la circulation du virus, tandis que les zones rurales, plus ou moins désertifiées, s’y prêtent beaucoup moins. Par ailleurs, les grandes zones périphériques, qui avaient anticipé d’une certaine manière une forme de confinement social, connaissent des problèmes complexes qui font varier l’intensité du germe perturbateur. Enfin, l’action publique, en jouant sur les circonstances précédentes, a naturellement la capacité de moduler l’intensité de la charge virale qui circule, ou d’en faire retarder les effets. C’est certainement ce qu’a voulu réaliser notre gouvernement, et c’est ce qu’il a annoncé avec l’objectif « d’aplatissement» de la courbe, mais le choix du confinement n’est qu’un pis-aller dans la mesure où il n’avait pas pu ou voulu contrer la dégénérescence programmée de notre système de santé qui s’était instaurée depuis une bonne trentaine d’années. Le recours à cet ultime moyen de lutte, qui repose sur la séparation spatiale en vue de diminuer la propagation humaine, devenait alors nécessaire afin au moins de protéger les parties les plus vulnérables de notre population (les gens âgés et les malades). De fait, la logique léthale du virus peut être en partie diminuée provisoirement pour un petit nombre, mais pas son issue collective fatale à terme. En sus de ces facteurs, il faut bien évidemment tenir compte des accidents particuliers et des autres circonstances qui peuvent altérer le décompte des cas et des pertes humaines.
La question des sources
C’est un principe méthodologique de base qui vaut aussi bien pour les statistiques que pour toute publication qui vise à s’approcher de la réalité du phénomène étudié. En l’occurrence, il y a plusieurs types de questions qui se posent ici, et d’abord celle-ci : quelles sont les séries de données les plus pertinentes et les plus significatives pour rendre compte de l’ampleur réelle de l’épidémie et de son évolution. La plupart des sources d’information, les médias et les milieux médicaux, donnent trois ou quatre variables principales : le nombre de cas déclarés, les entrées hospitalières ou le nombre de malades infectés en réanimation, et enfin les statistiques de décès constatés. Leur degré de pertinence varie considérablement selon les méthodes de mesure.
En ce qui concerne le nombre de cas, les données ne sont pas très solides en l’absence du dépistage systématique qui permettrait de connaître avec précision quels sont les gens infectés. Tout dépend de l’appareil statistique utilisé. En France, puisque l’épidémie a atteint le niveau 3 sur l’échelle des mesures administratives et que le confinement total est pratiquement réalisé, il s’agit principalement de données estimées par les autorités de santé, à partir des cas constatés officiellement. Comme nombre de personnes sont des porteur sains ou peu contaminés, ces cas ne sont pas reportés. Il en est de même pour ceux venant des EHPAD, qui sont très mal comptabilisés pour diverses raisons. Le réseau de médecins de ville ne fournit quant à lui qu’une information plutôt fragile. On sait que ce type de maladie virale tend à guérir spontanément lorsqu’il n’y a pas de facteur de comorbidité associé, pour au moins 80 à 85 % des cas, mais la difficulté est justement de définir quels sont ces cas en l’absence de tests fiables. Les hospitalisations et les entrées en réanimation donnent d’autres chiffres qui sont encore plus discutables, car dépendant des institutions qui les rapportent et se référant à des critères qui ne sont pas suffisamment harmonisés au niveau mondial. Seul le nombre des décès semble plus fiable et objectif, mais là encore les statistiques sont insuffisantes, car ce sont principalement les données des hôpitaux qui sont utilisées, ce qui laisse de côté les décès constatés en EHPAD (les pensionnaires souffrent souvent de plusieurs types de morbidité associés et décèdent donc de causes indéterminées), et ceux à domicile qui ne sont pas toujours reportés comme tels. Pour ma part, après plusieurs essais, j’ai choisi de ne retenir que les deux séries les plus utilisées, les cas de contamination avérés et les décès constatés. Ce faisant, je suis conscient de la fragilité relative de ces chiffres mais c’est leur utilisation généralisée, et médiatisée tous les jours, qui m’a convaincu.
Quant aux sources primaires, celles qui collectent les données et dont provient l’essentiel de l’information qui circule, il y a plusieurs possibilités : l’OMS (Organisation Mondiale de la Santé, ou WHO en anglais) qui publie un rapport mondial journalier, par pays et par grandes caractéristiques, mais dont le détail noie un peu le lecteur, qui est mis à jour avec un petit retard et qui se concentre à mon avis un peu trop sur l’actualité du moment ; le ministère de la santé et le gouvernement avec leur point quotidien (via le site Santé publique France) qui donne les chiffres officiels du jour ; certains sites statistiques en ligne comme worldometers.info qui recueille en temps réel toutes les données mondiales émises en les harmonisant et dont les chiffres sont repris par la plupart des grands journaux, des télés et des autorités ; et enfin l’INSEE, qui estime après coup les données démographiques nouvelles en les confrontant à la mortalité attendue afin d’obtenir par différence la « surmortalité » spécifique à l’évènement (comme cela avait été le cas lors de la grande canicule de 2003). Cette dernière source aurait a priori ma préférence mais elle présente l’inconvénient d’être longue à réaliser du fait des critères méthodologiques et de la lourdeur de l’appareil démographique. J’ai dû me rabattre sur la source la plus fiable dans l’immédiat, le site worldometers.info, qui présente l’avantage incomparable de produire régulièrement des séries longues, et surtout harmonisées, ce qui rend les chiffres comparables d’une période sur l’autre, soit le critère idéal pour un statisticien qui fonctionne selon le principe du calcul « à erreur constante » … De sorte que mon raisonnement s’est appuyé sur les chiffres de ce site relatifs au nombre de cas enregistrés et à celui des décès.
Les principes de construction du modèle
Ces bases ainsi posées, je me suis concentré sur un nombre limité de pays, en fait les trois premiers les plus frappés à l’origine et les plus médiatisés : la Chine, l’Italie et la France. En émettant l’hypothèse supplémentaire que la Chine était pratiquement sortie de fait de l’épidémie, si ce n’est pas encore du confinement (par précaution), et que son exemple constituait un modèle que devait suivre plus ou moins mécaniquement tous les autres pays qui y sont entrés plus tardivement, j’ai développé un raisonnement mathématique qui m’a conduit aux constatations qui suivent.
Tout d’abord, je souhaiterais mettre en évidence la similarité des courbes d’évolution des 3 pays, tant pour les « cas » que pour les « décès ». A cette fin, j’ai dû tenir compte du décalage temporel entre les séries, et j’ai dû les réajuster sur un même calendrier théorique de n périodes afin les faire toutes commencer au même moment 1. Le nombre « n » est donc différent selon les pays, égal à 66 pour la Chine (dont le cycle total est de l’ordre de 66 jours, soit un peu plus de 2 mois), 32 pour l’Italie et 24 pour la France qui est la dernière venue, et donc la période observée plus courte pour ces deux pays, puisque le cycle est encore en cours. L’axe de temps des deux graphiques ci-dessous a été tronqué afin de faire tenir ces séries plus petites dans le même intervalle de temps. Par ailleurs, afin d’éliminer les différences d’échelle entre les 3 pays, j’ai utilisé des indices de base 100 = 1 qui permettent de comparer strictement la progression des valeurs des séries.
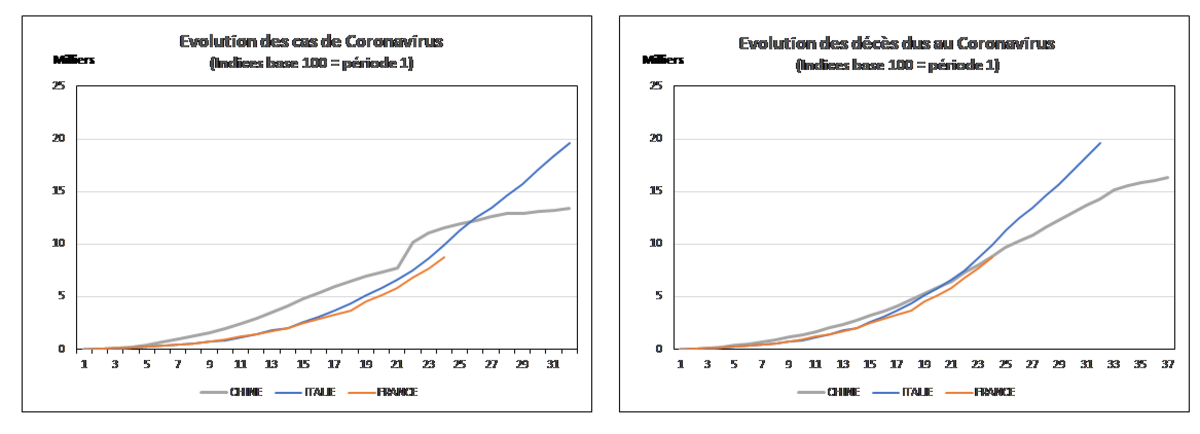
Agrandissement : Illustration 1
Comme on peut le constater dans le graphique de gauche, alors que le nombre de cas déclarés en Chine tend à ralentir au bout de 3 semaines (si l’on en croit les chiffres officiels), celui des Italiens continue à progresser jusqu’à la fin du premier mois et celui de la France est toujours en croissance au 24ème jour. Néanmoins, le plus remarquable c’est le parallélisme des courbes française et italienne qui ont un profil presque identique. C’est encore plus vrai pour les courbes de décès (graphique de droite), où les progressions chez les deux sœurs latines suivent la même évolution tandis que la mortalité totale ralentit en Chine et atteint progressivement un plateau.
Il ne faut pas oublier que ces séries représentent des valeurs cumulées et non la variation d’une période sur l’autre, qui est à mon avis plus significative. Dans les graphiques ci-dessous, je présente l’évolution des nouveaux cas et des nouveaux décès en Chine. Si ces chiffres sont avérés, on constate que la forme de ces courbes est proche de celle, théorique, de la courbe de Gauss (dite Normale, mais les anglo-saxons parlent plutôt de « bell curve » ou en cloche)[1], qui représente la distribution idéale d’un phénomène donné qui obéirait seulement au hasard[2], si le nombre de variables est suffisant[3].
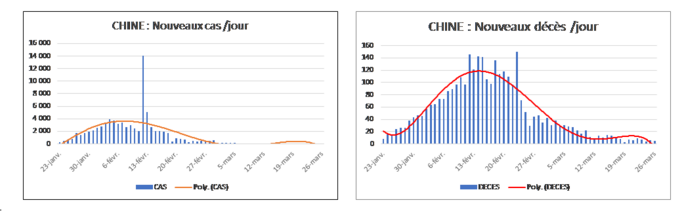
Agrandissement : Illustration 2
La distribution des nouveaux cas (graphique de gauche) est plus accidentée que celle des nouveaux décès (graphique de droite), qui obéit mieux au profil d’une loi Normale comme l’indique la courbe d’ajustement[4] (en rouge) qui lisse les évolutions observées. Si, en effet, on considère que les valeurs légèrement aberrantes ne sont liées qu’à de petits incidents qui perturbent la distribution gaussienne idéale, puisque l’ajustement graphique se fait empiriquement assez bien, force est de constater que le suivi du nombre de nouveaux décès représente le meilleur indicateur, et que l’on est le mieux en mesure de déterminer le pic ou le moment du basculement de la série représentative de l’épidémie.
On dispose là d’un modèle qui semble a priori assez bon, mais qui est plus descriptif qu’explicatif. L’interprétation du mouvement réel dépend plus à mon sens de l’écart entre les valeurs de celui-ci et celles observées. En d’autres termes, ce sont les petits incidents, ou accidents, qui nous renseignent le plus sur le comportement plus ou moins « déviant » du virus par rapport à sa norme, qui représente la dynamique intrinsèque du germe. Dans le cas chinois, qui nous sert de modèle, on constatera deux petits phénomènes : une instabilité certaine du moment où le pic est atteint, puisqu’il se produit sur une période d’une dizaine de jours sans que l’on puisse déterminer avec précision celui qui constitue à proprement parler le « pic » ; une chute plus brutale mais étalée en queue de comète dans la période de reflux. Ces caractéristiques se retrouvent également sur les modèles appliqués aux deux autres pays, car les données déjà observées vont dans le même sens, ce qui tend à légitimer cette méthode.
L’application du modèle à l’Italie et à la France
La distribution des cas et celle des décès est déjà en partie connue pour ces deux pays, mais on s’arrête seulement à mi-chemin, et on est proche du moment où le renversement va se produire, c’est-à-dire celui où le nombre de nouveaux décès (puisque c’est la variable qui me semble la plus significative) va commencer à diminuer de manière continue. Il semble évident au vu du modèle qu’il s’agit d’une période confuse qui est difficile à définir a priori, mais où les observations statistiques doivent suffisamment confirmer le mouvement descendant de la variable. Sans rentrer dans trop de détails sur les calculs fastidieux et ennuyeux, qu’il m’a fallu beaucoup de temps à effectuer, on peut simplement préciser que l’application du modèle aux distributions respectives de la France et de l’Italie implique plusieurs étapes assez élémentaires en soi. Il s’agit en fait d’opérer un glissement de la structure du modèle vers la distribution spécifique de chaque pays en alignant à la fois les périodes et l’amplitude des fluctuations sur le profil du modèle par des méthodes statistiques, afin d’obtenir non pas de nouvelles séries complètes, mais des séries partielles sur les périodes non encore observées. En d’autres termes, on complète les séries existantes par des données potentielles issues d’une projection de leur taux d’évolution basée sur celle du modèle. Le temps permettra de vérifier jour après jour la pertinence de ces estimations, et de parvenir à procéder à une analyse de la courbe réelle de propagation de la pandémie. Les résultats obtenus sont présentés dans les graphiques ci-dessous.
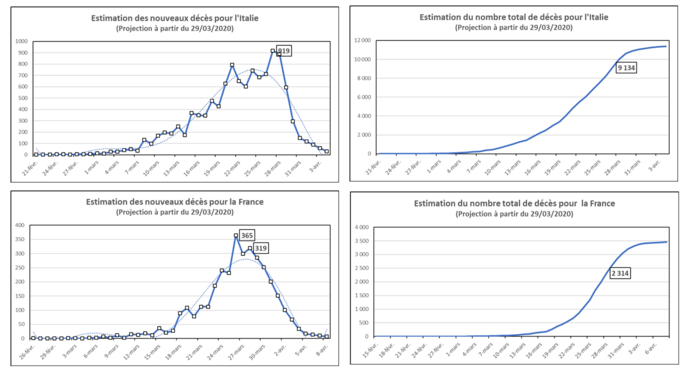
Agrandissement : Illustration 3
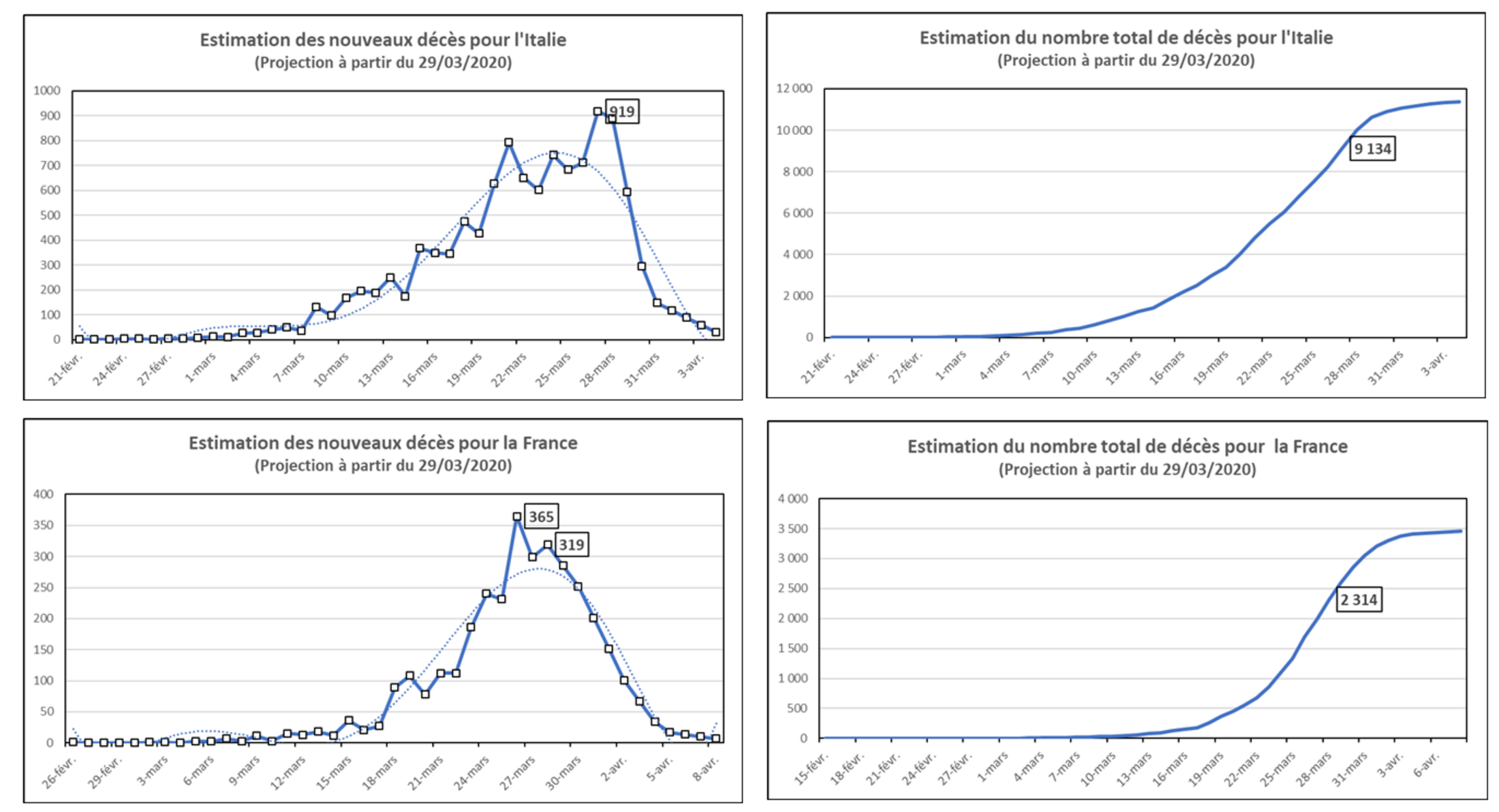
En ce qui concerne l’Italie, on s’aperçoit en premier lieu qu’il n’y a pas à proprement parler de véritable pic bien net, puisque cette courbe présente plusieurs sommets sur une période d’une semaine du 21 au 27 mars, et qu’il n’y a en fait à la place qu’une période de fluctuations plutôt indéterminées. Les dernières observations réelles portent sur une culmination du nombre des nouveaux décès à 919 le 28 mars, puis un début de baisse le lendemain à seulement 889 décès supplémentaires. Il peut être intéressant de noter que, comme la source nous l’apprend, les chiffres du 26 et du 27 avaient été initialement victimes d’une erreur de transcription de la Protection Civile dans le Piedmont qui avait abouti à la comptabilisation de 50 décès en trop, corrigée immédiatement par le site mais que certains médias importants n’ont pas toujours reprise (Corriere delle Sera, La Reppublica, BBC, Bloomberg, The Guardian) alors que d’autres l’on fait (The New York Times, Reuters, Financial Times, Al Jazeera, etc.). Ce petit incident montre la vulnérabilité de l’information. Selon notre modèle, cette baisse devrait néanmoins se poursuivre de manière brutale pour arriver à un niveau proche de 30 vers le 4 avril. En face, le graphique des décès cumulés montre un total observé de 9134 morts le 27 mars et 10 023 le 28 mars. La forme de la courbe révèle ainsi une inflexion dès le 27 qui correspond à une inversion de la pente (dérivée seconde nulle). L’Italie semble donc avoir déjà atteint le pic de retournement, bien que le nombre total de décès continue inévitablement à augmenter…
Quant à la France, sa situation est apparemment similaire, mais avec un profil plus clair puisque le pic des nouveaux décès est nettement atteint dès le 26 mars avec 365 morts. Toutefois les derniers chiffres enregistrés montrent un pic secondaire un peu plus bas le 28 mars avec 319 morts, ce qui semble indiquer que la résorption de l’épidémie n’est pas aussi régulière. Parallèlement, on retrouve un point d’inflexion sur la courbe cumulée pour le 26 mars avec un total de 3.314 décès. A partir du dimanche 29 mars, le modèle devrait évoluer régulièrement à la baisse, mais l’on peut se demander si ce profil sera bien confirmé par les faits, du moins selon les critères retenus.
Une prévision fragile et provisoire
Ma première remarque finale tient à la difficulté de suivre l’évolution en temps réel compte tenu de la durée nécessaire pour intégrer les données les plus récentes. Toutefois, j’ai pu faire figurer les derniers résultats de décès qui ont été enregistrés depuis dimanche 29 mars jusqu’à ce soir, et les résultats sont éloquents. Les séries présentent des « anomalies » croissantes sur les trois derniers jours, comme on peut le voir sur le petit tableau suivant qui vient d’être réalisé à l’instant :
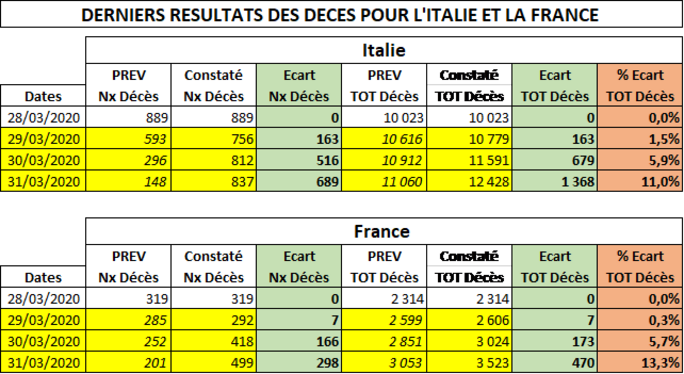
Agrandissement : Illustration 4
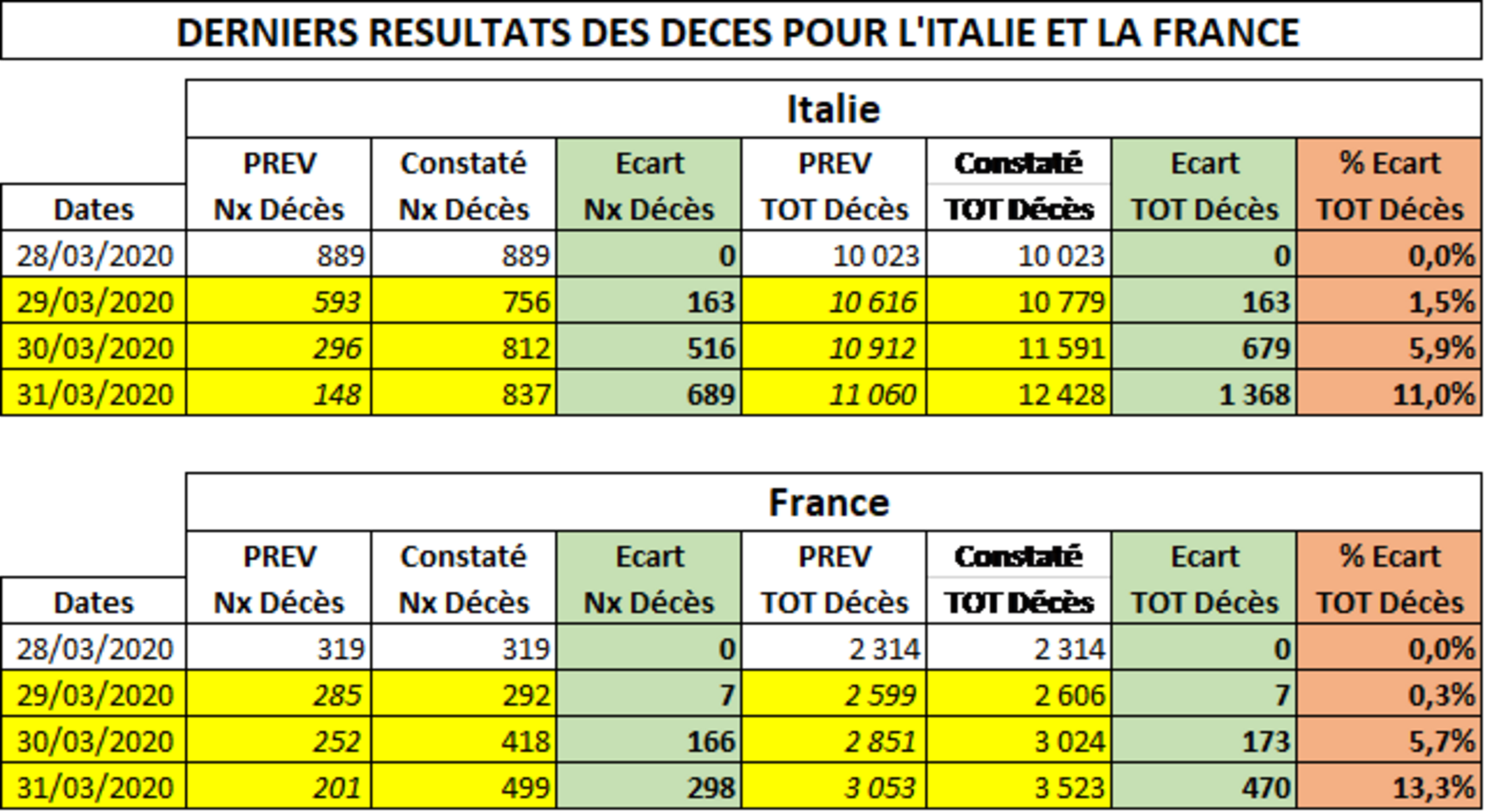
En Italie, le nombre des nouveaux décès s’est remis à croître, avec une progression de plus en plus rapide, et l’écart par rapport à la norme prévue est également croissant. Même si le 29 mars l’évolution semblait suivre un peu le profil attendu, la détérioration s’est accélérée les deux jours suivants. En termes de nombre de décès cumulé, l’écart par rapport à la prévision est énorme et représente 11,0 % du total des décès enregistrés le même jour, ce qui est a priori étonnant, et indique que la mortalité est en très forte hausse. On a vraisemblablement affaire à des facteurs extérieurs à la dynamique intrinsèque de l’épidémie. En France, le schéma est assez similaire, avec néanmoins un écart plus faible au départ, puis croissant à un rythme plus rapide. Au troisième jour, il représente alors 13,3 % du total des décès enregistrés le 31 mars. C’est supérieur au cas italien et l’aggravation de la situation sanitaire interroge le modélisateur. Si l’on considère que le modèle présenté ici constitue, sous certaine hypothèses et conditions, une réelle analyse de la logique interne propre au virus et de son évolution « normale », on doit alors admettre que ces « aberrations » statistiques sont significatives d’un état sanitaire pratiquement aussi délabré dans les deux pays, qui explique la surmortalité constatée, la dérive anormale des effets de la pandémie, dus à une gravité et des effets de retard exceptionnels.
[1] On parle alors de loi « Normale », caractérisée classiquement par sa moyenne arithmétique « m » et par son écart-type « ẟ », et notée N (m, ẟ). La distribution gaussienne représente la norme probabiliste idéale, parfaitement symétrique.
[2] Le hasard en statistique (et en probabilité) est souvent présenté comme un ensemble infini de causes trop faibles pour avoir chacune un effet notable sur la distribution d’une série d’évènements. Il est par définition opposé au déterminisme.
[3] Le nombre d’évènements ou de variables doit être en principe égal ou supérieur à 30 pour être significatif.
[4] Pour les puristes, la courbe de tendance correspond ici à une équation polynomiale de degré 5.