



les nouveaux défis de l'intelligence artificielle :

Agrandissement : Illustration 1

L'intelligence artificielle ne date pas de la semaine dernière. On pourrait dater sa naissance du fameux "test de Turing" écrit en 1950 et qui était destiné à mesurer justement la capacité d'une machine à "imiter" l'intelligence humaine. Et depuis, les progrès et les avancées successives des techniques ont produit des emballements subits suivi de périodes ou l'intelligence artificielle semblait appartenir au rang des promesses définitivement non tenues. On peut citer la période ou la cybernétique avait le vent en poupe,
La naissance officielle de l'intelligence artificielle comme discipline universitaire légitime date d'une conférence d'été donnée sur le campus du Darmouth college en 1956. Plusieurs grands noms de la recherche informatique de l'époque (Marvin Minsky, Claude Shannon, Hebert Simmon ou Nathan Rochester) se réunissent pour donner une viabilité informatique a leur recherche adoptée sous le nom d'intelligence artificielle. Allen Newell, Herbert Simon et Cliff Shaw conçoivent ensuite ensemble le "General Problem Solver" en 1957, qui est considéré alors comme le premier programme performant d'intelligence artificielle. D'autres programmes sont ensuite mis au point, concernant la traduction automatique par Margaret Masterman où les jeux stratégiques (dés cette période est mise au point le premier programme permettant un jeu efficace aux dames) Mais ces avancées n’empêchent pas une période de doute et de méfiance de s'instaurer dés le milieu des années 60.
Cette période de doute prendra fin à l'arrivée des "systèmes experts" et de l'informatique individuelle (micro informatique) Les systèmes experts sont des programmes permettant de mettre en œuvre une stratégie d'intervention dans divers domaines a partir d'une base de connaissance. Le plus connu des systèmes experts de cette période à été créé par deux informaticiens de l'université de Stanford Buchanan et Shortliffe dans le domaine médical. MYCIN est un système créé, avec succès, pour assister les médecins dans leur diagnostic et dans le traitement de certaines maladies bactérienne sanguines. Un autre domaine ou des progrès fulgurants sont attendus est la traduction automatique de langues étrangères.
Mais la aussi des progrès réels seront mis a mal par une communication par trop triomphaliste et la stagnation de certains domaines de recherche.
La situation va de nouveau se dégager quand de nouvelles technologies et de nouvelles façon de concevoir les algorithmes d'intelligence artificielle vont révolutionner le secteur et l'ouvrir à de nouvelles perspectives.
On appelle "paradigme de programmation" la façon qu'a un langage de programmation d’appréhender son environnement (informatique voir physique) Le langage de programmation le plus utilisé actuellement en IA actuelement est le Python, un langage "multi paradigme". Le nouveau "paradigme" en vogue s'appelle le "machine learning" et sa partie la plus prometteuse, le Deep learning.
Le Machine Learning
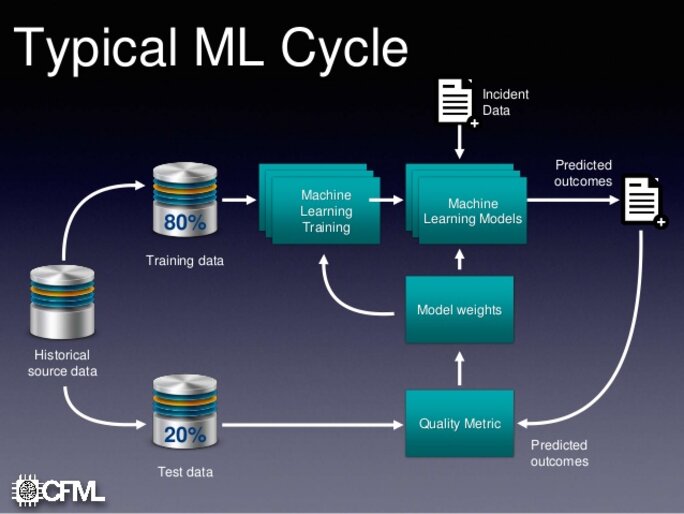
Agrandissement : Illustration 2
Quand on parle d'intelligence artificielle on parle en général de différentes techniques de "Machine Learning", d'apprentissage automatique. Le "Machine Learning" est un domaine particulier de l'intelligence artificielle qui concerne l'apprentissage automatique par un processus informatique d'extraction de résultats que l'utilisateur cherche a analyser en fonction d'un objectif. Les méthodes utilisées peuvent être extrêmement diverses, mais concernent essentiellement des techniques issues de processus d'analyse statistique, ou de mise en œuvre de réseaux de neurones artificiels (simulés par un processus informatique)
Ces techniques sont profondément différentes des approches informatiques traditionnelles. En effet dans ces dernières, le résultat des algorithmes est déterminée par le résultat de calculs dont on connait les tenants et les aboutissants. Dans les processus d'apprentissage automatique, le résultat dépend d'un apprentissage lui même dépendant de données dont on extrait le comportement particulier pour le généraliser à une classe de problèmes : par exemple, la reconnaissance de "chats" sur une image dépend d'une "base de connaissance" de multiples photos de cet animal.
Le caractère à la fois relativement "nouveau" et inédit de ces techniques permet de comprendre que celles ci sont en perpétuelles évolutions, et que les résultats qu'elles permettent d'obtenir sont eux même en révolution permanente. Les algorithmes que nous évoquerons sont les "briques de bases" telles qu'elles sont actuellement conçues. Mais elles sont en perpétuelle évolution du fait qu'on invente en permanence à la fois de nouvelles variations autour des "briques de bases" constituant le squelette des applications possibles mais aussi de nouvelles organisations possibles de ces "briques de bases". D'ou des mutations perpétuelles qui constituent en même temps l'infinie richesse mais aussi la difficulté du secteur.
Outre les algorithmes mettant en jeu les "réseaux de neurone profonds" dont on parle beaucoup, bien d'autres algorithmes sont mis en œuvre et combinés, selon le domaine d'application, le secteur d'origine des concepteurs de ces algorithmes (par exemple, les concepteur issus du secteur spacial et aéronautiques refusent à implémenter des algorithmes de deep learning en raison du caractére "non prédicatifs" de ces algorithmes (en général, on sait que "ça marche" mais on ne sait pas trop pourquoi)
On peut citer dans les principaux algorithmes utilisés par le "machine learning" :
Le K means : c'est une méthode d'analyse statistique classique : le "partitionnement en K moyennes", une méthode de partitionnement de données et un problème d'optimisation combinatoire. "Étant donnés des points et un entier k, le problème est de diviser les points en k groupes, souvent appelés clusters, de façon à minimiser une certaine fonction. On considère la distance d'un point à la moyenne des points de son cluster ; la fonction à minimiser est la somme des carrés de ces distances." (merci Wikipedia)
la régression linéaire : Les algorithmes de régression linéaire modélisent la relation entre des variables prédictives et une variable cible. La relation est modélisée par une fonction mathématique de prédiction. Le cas le plus simple est la "régression linéaire univariée". Elle va trouver une fonction sous forme de droite pour estimer la relation. La régression linéaire multivariée intervient quand plusieurs variables explicatives interviennent dans la fonction de prédiction. Et finalement, la régression polynomiale permet de modéliser des relations complexes qui ne sont pas forcément linéaires
La régression logistique est une méthode statistique pour effectuer des classifications binaires. Elle prend en entrée des variables prédictives qualitatives et/ou ordinales et mesure la probabilité de la valeur de sortie en utilisant la fonction sigmoïde
En mathématiques, la fonction sigmoïde (dite aussi courbe en S1) est définie par :

mais on la généralise à toute fonction dont l'expression est :

Elle représente la fonction de répartition de la loi logistique et est souvent utilisée dans les réseaux de neurones parce qu'elle est dérivable ce qui est une contrainte pour l'algorithme de rétropropagation qui a permisde créer des réseaux multicouches
Machine à Vecteurs de Support (SVM) est lui aussi un algorithme de classification binaire, a l'instar de la régression linéaire, plus efficace pour tout une catégorie de problémes.
Naïve Bayes permet de distinguer plusieurs ensembles de données et il est assez intuitif à comprendre. Il se base sur le théorème de Bayes des probabilités conditionnelles. Naïve Bayes assume une hypothèse forte : il suppose que les variables sont indépendantes entre elles. Cela permet de simplifier le calcul des probabilités, même si cette hypothése est souvent erronée (d’où le "naïf"). Généralement, le Naïve Bayes est utilisé pour les classifications de texte
Le royaume enchanté des données

Agrandissement : Illustration 5

L'intelligence artificielle et ses déclinaisons (machine learning et réseaux de neurone) ne rencontrerait pas un succés éclatant si on assistait pas aussi à une révolution dans le domaine des données : c'est tout ce que les publicitaires ont nommé "big data", c'est a dire des données d'une taille considérables, qu'il s'agit alors de traiter, découvrir des régularités a partir d'analyses statistiques.
Les premiers outils mis au point concernant les "big data" ont permis d'adopter de nouvelles façons de traiter les données. Jusque là, on pensait avoir atteint le Graal en mettant en œuvre ce qu'on a appelé les "bases de données relationnelles". Celles ci permettent de traiter des données de grande ampleurs (plusieurs millions d'enregistrement) via un langage spécialisé dans leur consultation, le SQL (structured Qwery Langage : langage de requête structuré) Malheureusement les bases de données relationnelle imposent un modèle d'architecture spécialisé "client serveur". Or l'explosion des données implique que les données soient réparties : Google recense ainsi 26 milliards de pages web avec une estimation de 900000 serveurs dans le monde. Dans ce cadre, Google a mis au point une nouvelle sorte de "base de données" qu'on nomme "NOSQL" (puisqu'elles ne peuvent plus utilisé le langage de requête normalisé) et qu'elle a décliné en une application "libre" : Hadoop Ce dernier est un framework applicatif en java permettant de gerer de grandes quantité de données (de l'ordre de plusieurs Pétaoctets, un Pétaoctet étant égal à un million de Gigaoctets) de façon répartie (sur plusieurs milliers de serveurs) Mais ces solutions ne permettent que de stocker de grandes quantités de données, pas de les traiter ou d'en extraire l'or des données...
C'est là ou le machine learning intervient, car il est à ce jours la technique la plus performante pour traiter de façon efficace ces données. Mais les résultats qu'il propose dépend en grande partie de la qualité des données recueillie.
Dans le monde réel, les données proviennent de plusieurs sources et processus. Elles peuvent contenir des anomalies ou des valeurs incorrectes qui compromettent la qualité du jeu de données. Les problèmes de qualité les plus fréquents sont les suivants :
- Caractère incomplet :des valeurs ou des attributs sont manquants.
- Bruit :les données contiennent des enregistrements erronés ou des aberrations.
- Incohérence :les données contiennent des enregistrements en conflit ou des contradictions.
La qualité des données est essentielle pour obtenir des modèles prédictifs performants. Pour éviter de traiter des données erronées et améliorer la performance du modèle, il faut impérativement analyser les données, détecter les anomalies le plus tôt possible et déterminer les étapes de prétraitement et de nettoyage appropriées.
l’apprentissage
Dans l'apprentissage automatique, les tâches sont généralement classées en grandes catégories. Ces catégories sont basées sur la façon dont l'apprentissage est reçu ou comment le feedback sur l'apprentissage est donné au système développé.
Deux des méthodes d'apprentissage automatique les plus largement adoptées sont l' apprentissage supervisé qui forme des algorithmes basés sur des données d'entrée et de sortie étiquetées par l'homme et l'apprentissage non supervisé qui ne fournit pas à l'algorithme des données étiquetées pour lui permettre de trouver une structure et de découvrir une logique dans données entrées. Explorons donc ces méthodes plus en détail.
Dans l'apprentissage supervisé, l'ordinateur est fourni avec des exemples d'entrées qui sont étiquetés avec les sorties souhaitées. Le but de cette méthode est que l'algorithme puisse «apprendre» en comparant sa sortie réelle avec les sorties «enseignées» pour trouver des erreurs et modifier le modèle en conséquence. L'apprentissage supervisé utilise donc des modèles pour prédire les valeurs d'étiquettes sur des données non étiquetées supplémentaires.
Dans l'apprentissage non supervisé, les données sont non étiquetées, de sorte que l'algorithme d'apprentissage trouve tout seul des points communs parmi ses données d'entrée. Les données non étiquetées étant plus abondantes que les données étiquetées, les méthodes d'apprentissage automatique qui facilitent l'apprentissage non supervisé sont particulièrement utiles.
L'objectif de l'apprentissage non supervisé peut être aussi simple que de découvrir des modèles cachés dans un ensemble de données, mais il peut aussi avoir un objectif d'apprentissage des caractéristiques, qui permet à la machine intelligente de découvrir automatiquement les représentations nécessaires pour classer les données brutes.
prédicateurs et classificateurs
L'apprentissage que ce soit dans des processus de Machine Learning assez généralistes ou de Deep Learning se fondent sur deux processus différents mais convergent : celui qui permet de définir des "précicats" (un "prédicateur" donc) et celui qui permet de classer dans diverses catégorie des données complexes, en fonction d'un ensemble de critéres complexes, les classificateurs)
Le premier dispositif simple mis en œuvre dans les différentes techniques de "Machine Learning" c'est le "prédicteur" : celui ci permet d'obtenir un résultat a partir de données sans connaitre la fonction qui permet de passer de l'un à l'autre (sinon, on est plutôt dans de l'informatique "classique" ou un algorithme de calcul permet de déterminer à coup sur le résultat ) Evidemment, les différentes situations possibles entrainent souvent une grande complexité pratique du probléme, en particulier quand l'évolution des données n'est pas linéaire.
L'autre dispositif courant, c'est le "classificateur" qui permet de ranger des données selon des catégories déterminées. L’exemple de référence en machine learning, (son « hello world », pour les habitués à la programmation) c’est la classification des iris : on veut déterminer à quelle espèce un iris appartient. C’est assez simple car on peut catégoriser (le terme exact en machine learning est classification) un iris en fonction de 2 caractéristiques : la longueur et la largeur d’un pétale. Il nous faut tout d’abord un jeu de données d’iris avec ces 2 informations et l’espèce correspondante. Graphiquement, cela donne à peu près ça :
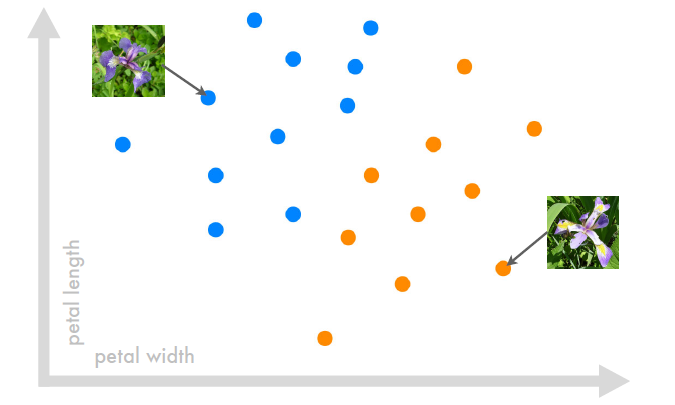
De nombreux frameworks (outils de conception logiciel consistant en une série de fonctions ou d'objets, et une "logique" d'utilisation de ceux ci) de "Machine Learning" implémentent cette série de données sur les Iris et un ensemble d'exercice permettant de mettre en œuvre les outils de programmation qu'ils proposent. Cet entrainement permet une première approche de ces outils, mais n'épuise pas la situation. En effet, la cohérence et la qualité des données est au moins aussi important que les différents algorithmes utilisés.
les réseaux de neurone
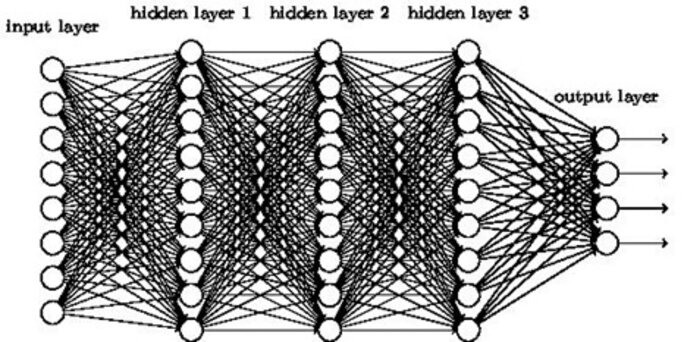
Une approche totalement différente pour résoudre le même type de problème fait appel à ce qu'on appelle des "réseaux de neurone profonds", c'est ce qu'on appelle le "Deep Learning/ L'utilisation d'un neurone artificiel n'a rien de récent. Il ne fonctionne jamais seul, mais dans le cadre d'un "réseau de neurone" dont le premier exemple historique fut le perceptron.
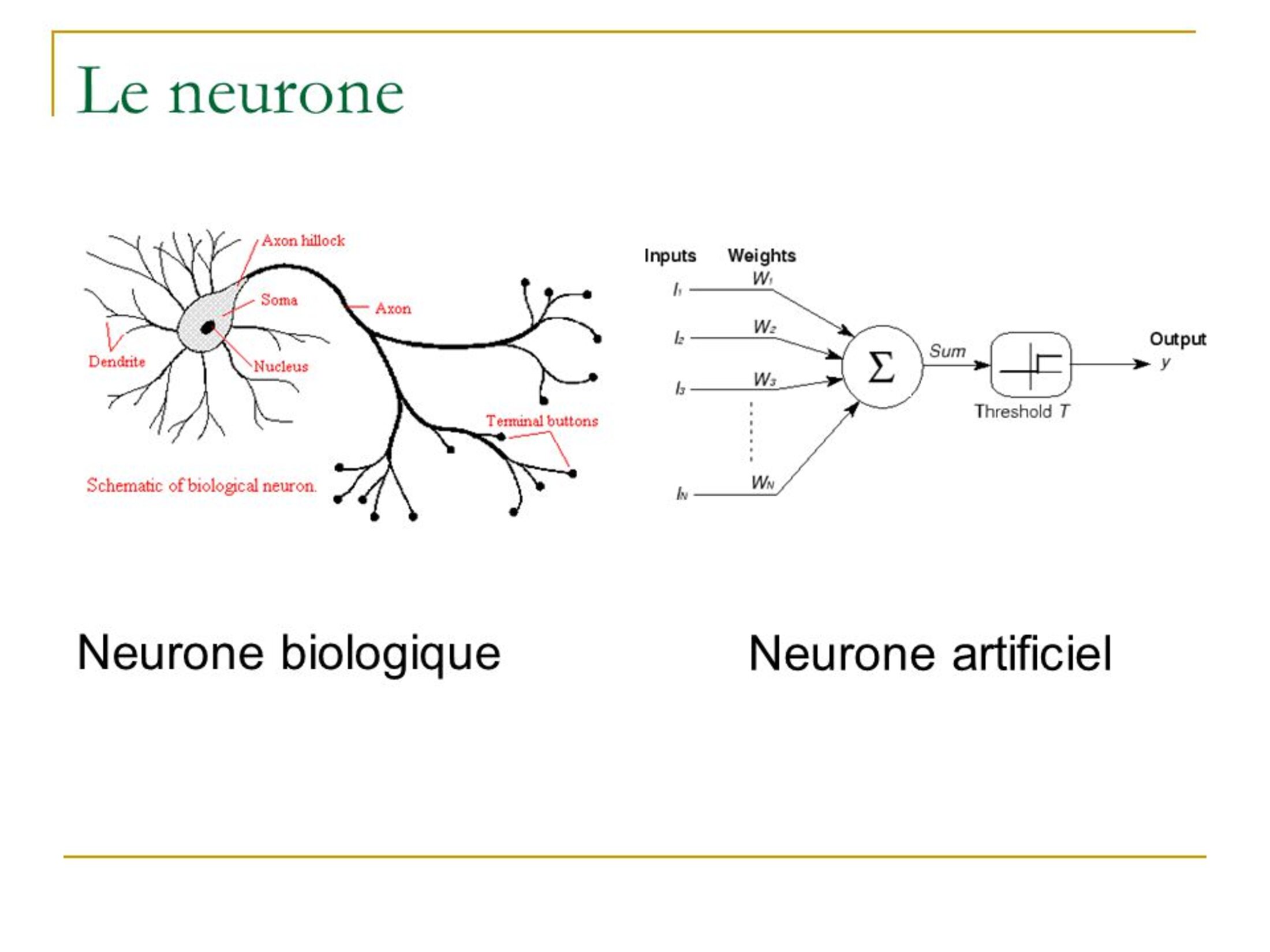
Mais avant cette première réalisation ce sont deux scientifiques, l'un logicien, Walter Pitts l'autre Warren McCulloch chercheur en neurologie vont creer un nouveau dispositif électronique, le "neurone formel". Celui ci est une représentation mathématique et informatique d'un neurone biologique. Il posséde de multiples entrées munies d'un coefficient multiplicateur pouvant être ajusté, une fonction "somme" ainsi qu'une fonction d'activation au seuil généralement non linéaire, et une sortie dont le résultat est ajusté en fonction de la phase d'apprentissage.
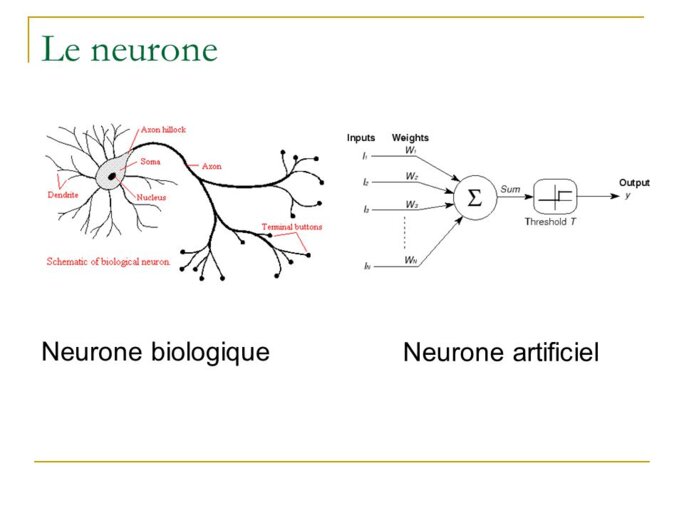
Agrandissement : Illustration 8
Ces "neurones formels" vont être reliés entre eux dans le premier exemple de "classificateur" opérationnel, le Perceptron. Celui ci est inventé en 1957 et est composé de 40 neurones. Il a été inventé en 1957 par Frank Rosenblatt au laboratoire d'aéronautique de l'université Cornell. C'est un modèle inspiré des théories cognitives de Friedrich Hayek et de Donald Hebb. Dans un premier temps, il s'inspire des déambulations de rats dans un labyrinthe (en essayant de prévoir ou les rats vont aller) mais l'utilisation finale du système permet d'identifier des lettres de l'alphabet. Cette découverte fera dans le milieu de l'intelligence artificielle l'effet d'une bombe Mais ce résultat étonnant sera suivi d'un contrecoup, un livre de deux des plus grands spécialistes de l'IA dans les années 60, Seymour Papert et Marvin Minsky qui montre toutes les limites du Perceptron tel qu'il est connu alors.
Les premiers réseaux de neurones n'étaient pas capables de résoudre des problèmes non linéaires ; cette limitation fut supprimée au travers de la rétropropagation du gradient de l'erreur dans les systèmes multicouches, proposé par Paul Werbos (en) en 1974 et mis au point douze années plus tard, en 1986 par David Rumelhart (en). Dans le Perceptron multicouche à rétro-propagation ces limites sont repoussées par l'effet de l'algorithme de "rétro-propagation" qui induit un effet retour qui corrige certains des défauts spécifiques au Perceptron
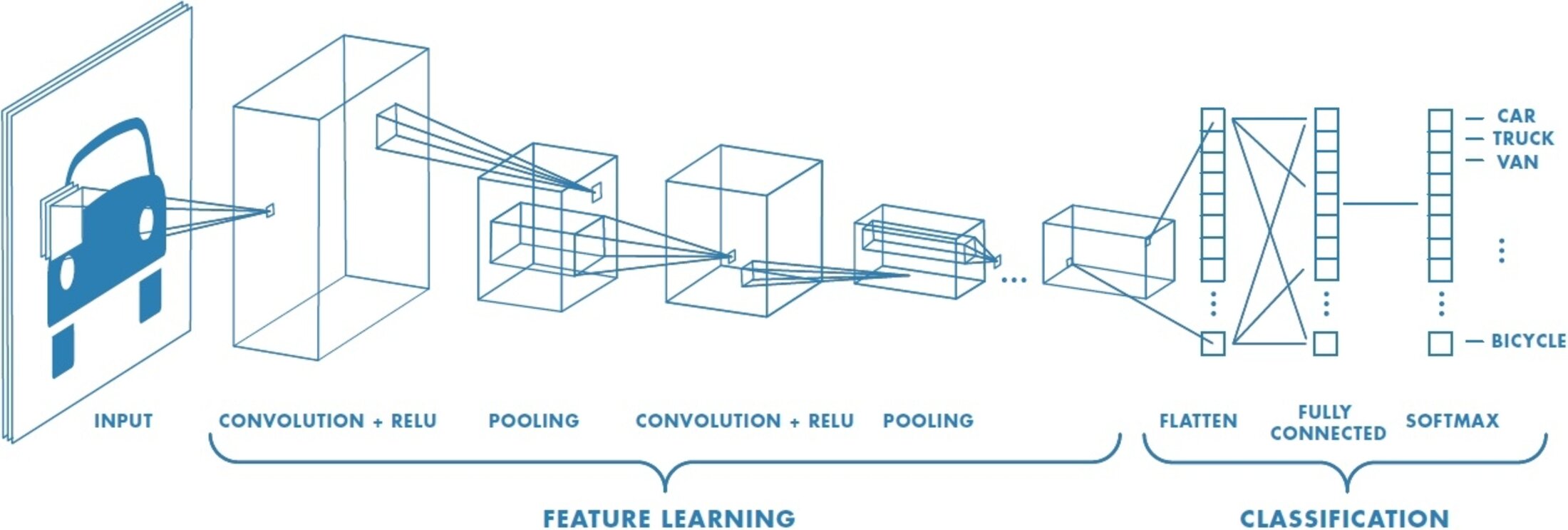
Ces limites seront totalement dépassées par la mise au point d'un autre type de réseau, le réseau "profond" ou les couches successives de neurones sont multipliées autant de fois que possible (il existe maintenant des "réseaux profonds" ou les couches "intermédiaires" de neurones se comptent en dizaine. L’idée du Deep Learning n’est pas une idée récente mais elle date en réalité des années 1980, plus particulièrement suite aux travaux de réseaux de neurones multi-couches et aux travaux de certains pionniers du machine learning et du Deep learning comme le français Yann Le Cun. En collaboration avec deux autres informaticiens , Kunihiko Fukushima et Geoffrey Hinton, ils mettent au point un type d'algorithme particulier appelé Convolutional neural network. trés performant dans l'analyse d'images.
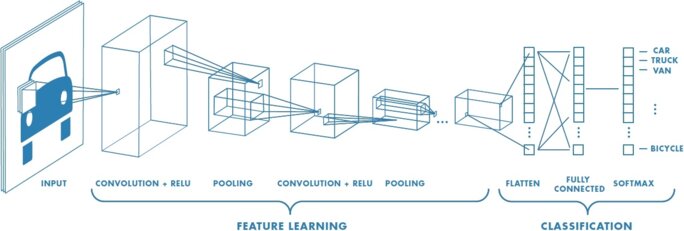
Agrandissement : Illustration 9
Bien que cette approche donne des résultats, ses progrès et son évolution sont limités par les progrès technologiques en matière de micro-processeurs, de puissance de calculs, et du manque d’accessibilités à des données afin de pouvoir entraîner les neurones. Cependant certains chercheurs ont continué à travailler sur ce modèle pendant environ deux décennies et, avec l’aide des évolutions en matières de technologies mais surtout avec la disponibilité toujours plus grande de données, ont pu améliorer cette technique.
L'explosion des données consécutive à l'apparition du big data va totalement bouleverser la donne et redonner aux différents "réseaux de neurone" toute leur actualité et leur importance.
La "seconde révolution des réseaux de neurone est due a l'apparition de nouveaux processeurs, et en particulier de processeurs "massivement parallèles" Ceux ci ont été dans un premier temps été utilisés dans les circuits graphiques de nos micro ordinateurs calculateurs graphiques GPU et de circuits programmables FPGA, qui a rendu possible l’explosion récente du Deep Learning. Nvidia est le plus connu des fournisseurs de GPU et il est aussi le principal fournisseurs de solutions intégrées pour le deep learning mais preuve de l'importance de cette technologie, Intel se lance lui aussi dans des solutions avec des processeurs "massivements paralléles"
C'est l'ensemble de ces progrés qui permettent la révolution apportée par les derniéres application du Deep Learning. Qu'on songe à la révolution apportée par DeepMind, le programme de jeu de go mis au point par une filiale de Google. Alors que le jeu de Go était réputé improgrammable, la mise au point de Alphago a été comme une explosion dans un ciel sans nuages.
Mais il faut se méfier quand même de l'aspect "communicationnel" de cette application. Par exemple, on explique beaucoup que la nouvelle version d'alphago Zéro "n'a pas besoin d'humain". Sauf que c'est faux ! Effectivement, on a modifié l'application capable maintenant de passer du mode "non supervisé" au mode "supervisé". C'est effectivement un progrés considérable, mais cela ne permet pas pour autant de prétendre qu'on peut "se passer de l'humain". Cette affirmation reléve bien plus du fantasme (ou de la propagande) que de données objectives.
Du coté des joueurs, l'heure n'est pas du tout à la résignation. Bien au contraire ! La victoire du programme a été la conséquence de coups extrêmement surprenants, alors que les techniques (humaines) du jeu de go résultent d'une longue histoire qui a fondé une "culture" qui entraine une certaine forme d'analyse, des ouvertures (le Fuseki) à la fin de jeu. Et si AlphaGo a gagné, c'est surtout parce qu'il a trouvé des coups surprenants, impossibles, ceux qui étaient rejeté dans "le canon du jeu". Maintenant, les grands maitres analysent comment AlphaGo a révolutionné cet aspect du jeu (qu'on croyait réglé depuis pas mal de siècles) Ce qu'ils pensent y trouver risque d’être passionnant ! (le rédacteur de ces ligne est un passionné de Go, et un très mauvais joueur)

Agrandissement : Illustration 10

Outils et frameworks :
Tout un ensemble d'outils vous sont proposés afin de pouvoir mettre en oeuvre un systéme de machine learning. Il y a d'abord tout un ensemble de fonctions proposées en paralléle avec Python, un des langage de programmation trés souvent utilisé pour mettre en oeuvre une application en Machine Learning ou Deep Learning. Scikit-Learn est le plus connu de ces bibliothéques de fonction mais il en existe bien d'autres.
Il existe également des environnements complets de programmation offerts par les principaux intervenants du secteur :
TensorFlow, proposé par Google offre une série d'API en python, C++, Java, etc Caffe2 est lui proposé par facebook dans une optique "outil de production" (Facebook propose également Pytorch et Torch comme outils d'expérimentation). et Apache MXNet qui se présente comme "un framework d'apprentissage rapide et dimensionnale MXNet inclut l'interface Gluon qui permet aux développeurs de tous niveaux de compétence de bien démarrer avec l'apprentissage en profondeur sur le cloud, les emplacements périphériques et les applications mobiles."
Il existe également des plates formes "sur le cloud" permettant à des entreprises de taille moyenne une véritable production a des tarifs raisonnables (pour mémoire, un outil comme le processeur permettant de véritables applications métiers coute au minimum 150000 $) Les quatre principales propositions sont implémentées par Amazon (sa plate forme AWS est la plus connue) Microsoft, IBM et Google Cloud.
Conclusion :
Le "machine learning" est une sorte d'extention des "big data". Celles ci sont en train de révolutionner notre monde, et de faire de celui ci une sorte d'utopie de mathématicien, un univers ou tout se conclue par un calcul. A partir de données multiples (qu'elles résultent de nos multiples traces de nos navigations sur des univers numériques sur lequels nous naviguons ou de l'arrivée prochaine de l'internet des objets (internet of things) se constuit une société de connaissance et de surveillance. Pour quoi faire, et selon quelle modalités ? Mystére ! Même les multiples algorithmes de Deep Learning qui sont pourtant dans le domaine public en théorie sont nimbés de mystére.
En résulte un paradoxe, celle d'une société prétenduement "de transparence" qui cultive pourtant le secret.
Bibliographie :

Il existe de multiples ouvrages sur le deep et le machine learning. J'en ai utilisés principalement quatres pour préparer ce billet :
Pirmin Lemberger, Marc Batty, Médéric Morel, Jean-Luc Raffaëlli Big data et machine learning, Dunod 2016 255 page : un ouvrage d'initiation qui présente les principaux concepts. Assez exhaustif, il est idéal pour le non informaticien. Sans programmation détaillée, ni mathématiques difficiles, il permet d'appréhender un paysage en perpétuelle mutation, ou les progrès sont quotidien
Andréas C. Muller et Sarah Guido Le machine learning avec Pÿthon O'reilly 2018 316 page : un manuel d'apprentissage des principales techniques de data learning (et de deep learning) avec Python. Doit être utilisé "machine en main" (il faut réaliser les exemples et exercices proposés) Très clair (les exemples marchent, et les exercices ne sont pas d'une difficulté décourageante)
Jean Claude Heudin Intelligence artificielle : manuel de survie Édition Science Ebook 2017 167 pages : un guide extrêmement facile d’accès qui tente (le plus souvent avec succès) de décliner les différents aspects de l'intelligence artificielle, de son histoire, de ses sucés et de ses échecs.Contient un glossaire et une bibliographie (la plupart des ouvrages étant en anglais, mais c'est malheureusement le lot de l'informatique)
Jean Claude Heudin Deep learning, une introduction aux réseaux de neurones Édition Science Ebook 2017 179 pages : Bien plus technique que le précédent, il permet d'appréhender de façon extrêmement claire le fonctionnement d'un réseau de neurone au travers d'application à réaliser autour d'un framework spécialisé écrit en JavaScript. Il ne propose par contre aucune explication générale de la programmation proprement dite, ce qui fait que vous ne pourrez, si vous n'y connaissez rien, que taper les réalisations proposées sans vraiment comprendre ce que vous faites. Cinquante pages d'initiation à la programmation n'auraient pas forcément été de trop.