



Redresser un sondage. Rien que le mot suffit à faire froncer les sourcils. Dans le langage courant, on imagine un tour de passe-passe, une manipulation silencieuse pour ajuster les résultats. Des chiffres qu'on "corrige" en coulisses pour les faire coller à une idée préconçue. C'est d'ailleurs une des critiques récurrentes exprimées lors de la récente commission d'enquête sur les sondages électoraux : que valent des chiffres qui ne sont pas ceux donnés par les gens, mais ceux "obtenus après redressement" ?

Agrandissement : Illustration 1

Et pourtant, redresser, ce n'est pas tricher. C'est, au contraire, souvent le seul moyen d'améliorer la qualité des estimations produites par un sondage. Encore faut-il comprendre pourquoi on le fait, sur quoi on s'appuie, et ce que cela implique. Car si le redressement est une technique puissante, il n'est pas magique. Il révèle autant les failles d'un sondage qu'il n'en répare.
Un sondage, c'est un échantillon. Et qui dit échantillon dit non-réponse. Toutes les personnes contactées ne répondent pas. Pire : la non-réponse n'est pas aléatoire. Ce sont souvent les mêmes profils qui ignorent les enquêtes : les jeunes, les précaires, les désintéressés de la politique. Conséquence : l'échantillon réel ne reflète pas la population que l'on cherche à décrire. Il faut donc corriger cela. C'est le rôle du redressement : recentrer l'estimation vers la cible, c'est-à-dire la population totale, pas seulement celle qui a accepté de répondre.
Agrandissement : Illustration 2
Comment fait-on ? En ajustant les poids des répondants pour que certaines caractéristiques connues (sexe, âge, région, niveau de diplôme, comportement de vote passé...) correspondent aux répartitions de la population. Si les femmes sont sous-représentées dans l'échantillon, on augmente leur poids pour qu'elles pèsent autant que dans la population. Cela paraît évident, mais c'est une opération lourde de conséquences. Car on attribue alors beaucoup de poids à certaines observations, ce qui peut fragiliser les résultats si ces personnes sont peu nombreuses. Ce redressement est réalisé par tous les instituts statistiques, qu'ils soit d'opinions politiques, ou de statistique publique. Et c'est une étape important pour éviter un biais systématique des résultats bruts.
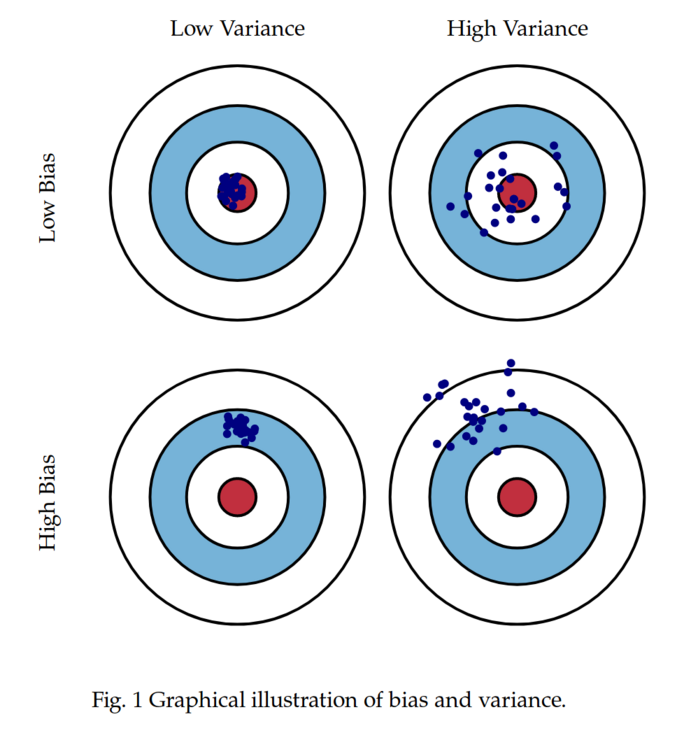
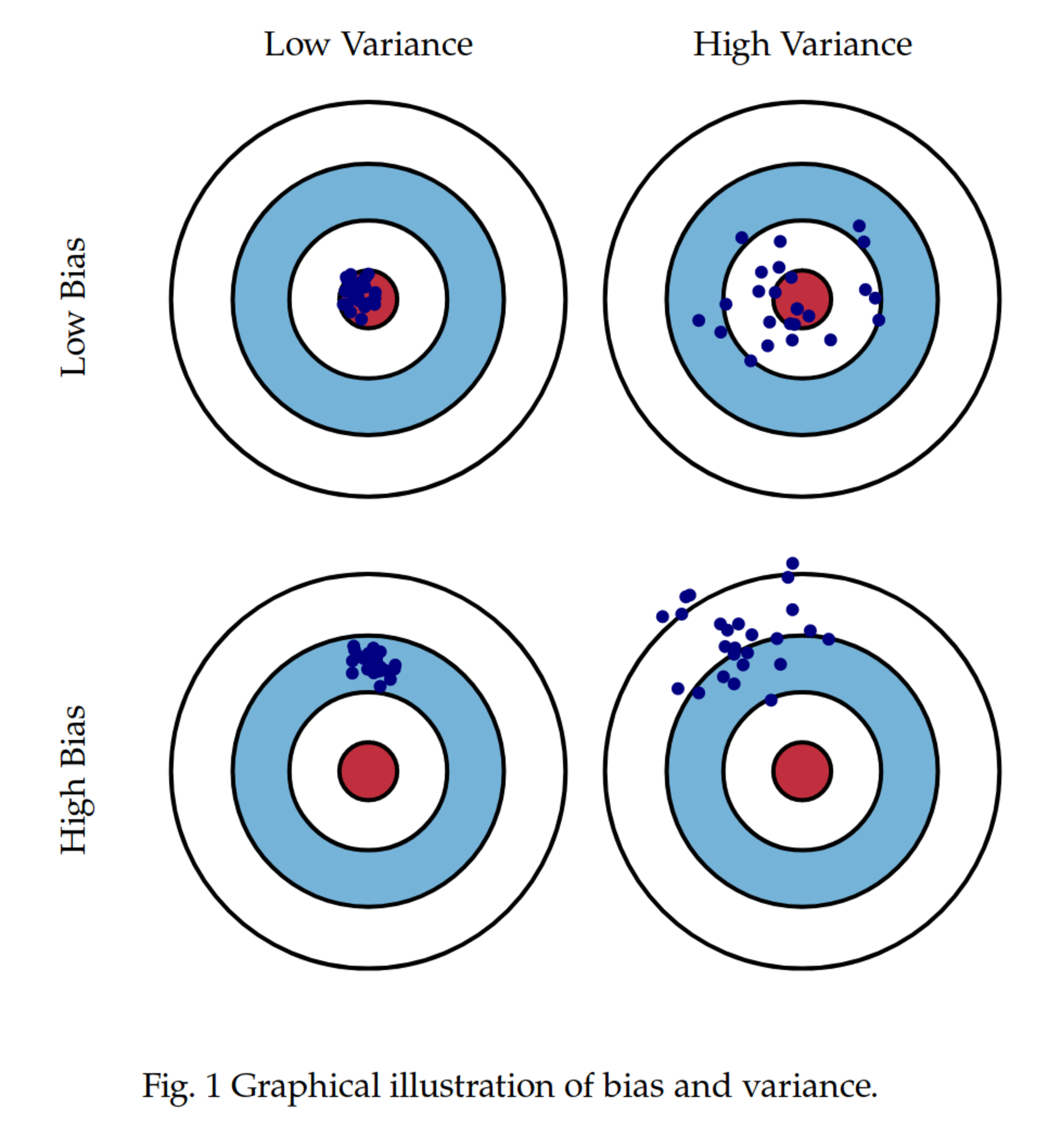
Le redressement a aussi une autre vertu moins connue : il permet de réduire la variance des estimations. En calant les poids sur des variables fortement corrélées à l'indicateur que l'on cherche à estimer, on transfère une partie de la variance vers ces variables auxiliaires, et ce qu'il reste à estimer n'est plus que le résidu. Exemple simple : si on veut connaître le revenu moyen d'une population, et qu'on sait parfaitement comment se répartissent les ménages selon leur niveau de diplôme (et que le revenu est très lié au diplôme), alors caler sur ce niveau permet de beaucoup réduire l'incertitude sur l'estimation finale. On remplace un estimateur direct (avec une variance forte) par un estimateur conditionnel sur une variable contrôlée (avec une variance moindre). Il y a un peu de mathématique derrière (de la regression linéaire), mais l'effet est simple et net. Encore faut-il avoir des variables de calage, encore faut-elles qu'elles soient bien corrélées à la variable d'intérêt.
Mais ne nous méprenons pas : le redressement ne corrige pas tout. Il ne corrige que ce qu'on est capable d'observer. Si vous n'avez pas d'information sur l'origine sociale, la fréquence de lecture de la presse ou le rapport au politique, vous ne pouvez pas corriger les biais associés à ces variables. Le redressement repose donc sur une hypothèse forte : que les variables disponibles suffisent à rendre les réponses conditionnellement indépendantes de la participation au sondage. Autrement dit, qu'une fois qu'on a pris en compte sexe, âge et vote passé, il n'y a plus de différence entre les répondants et les non-répondants. C'est souvent faux. Mais on fait comme si. Faute de mieux.
Et surtout, le redressement ne corrige pas le biais initial de recrutement. Dans un sondage par access panel, comme ceux utilisés par la plupart des instituts aujourd'hui, on ne tire pas les gens au sort : ils se sont inscrits volontairement. Ce ne sont pas "les Français", mais "les Français qui s'inscrivent sur un site de sondage pour répondre à des questionnaires". Et même si vous redressez derrière, vous ne pourrez jamais faire apparaître ceux qui n'étaient pas là dès le départ.
Autre conséquence peu visible du redressement : les poids attribués aux répondants peuvent être très hétérogènes. Si votre échantillon contient 10% de femmes et 90% d'hommes, et que la population cible est à 50/50, vous devrez multiplier par 9 les poids des femmes. Chaque répondante comptera alors autant que neuf répondants masculins. Le chiffre global est redressé, mais il est soutenu par des poids très asymétriques. Cela augmente l'incertitude, fragilise les analyses de sous-groupes, et complique les comparaisons temporelles.
Durant la commission, le responsable de l'Ifop a utilisé un argument censé clore le débat : "nos redressements sont basés sur les données de l'Insee, donc c'est fiable". Mais que signifie réellement cette phrase ? L'Insee ne fournit pas les personnes interrogées. Il fournit des distributions statistiques : combien il y a d'hommes, de femmes, de cadres, d'ouvriers, de personnes de 25 à 34 ans en Bretagne, etc. Ces chiffres permettent de redresser, une fois les données collectées, pour que l'échantillon "colle" à la structure de la population.

Agrandissement : Illustration 3

Mais cela n'améliore en rien la qualité de l'échantillon initial. Si le panel est constitué de volontaires auto-inscrits, biaisés par leur appétence politique, leur niveau de diplôme ou leur disponibilité, la structure sociodémographique ne garantit aucunement que leurs opinions soient représentatives. Appliquer les taux de l'Insee à un panel non aléatoire, c'est comme ajuster la forme d'un miroir déformant pour qu'il rentre bien dans un cadre. Certes, mais le reflet reste bancal.
Le glissement est subtil mais fondamental : ce n'est pas parce qu'un panel est redressé sur des chiffres publics qu'il devient représentatif. C'est juste qu'il a l'air plus sérieux. Le jargon statistique agit ici comme un cache-misère. L'Ifop ne dit pas "on a un bon échantillon", il dit "on a redressé avec un filtre Insee notre échantillon", pour nous convaincre.
On pourrait éviter cela en recrutant mieux dès le départ. Par exemple, si vous savez que vous allez redresser sur le vote à l'élection précédente, pourquoi ne pas faire un recrutement par quotas sur cette variable ? Parce que certains profils sont plus difficiles à atteindre. Les instituts admettent, par exemple, avoir du mal à recruter des électeurs de Jean-Luc Mélenchon. Cela dit quelque chose sur les biais structurels de leur panel. Si votre base ne contient pas assez de certains profils, le redressement ne peut que les surpondérer artificiellement. Et vous construisez alors un sondage où certains répondants comptent pour dix. Est-ce toujours une "photographie de l'opinion" ?
Un dernier point autour de cette difficulté d'obtenir des bons échantillons bruts pour certains candidat·es et la réponse des institus de sondage. L’Ifop avance dans le même paragraphe deux arguments pour expliquer que les sondages par téléphone sous-estimaient historiquement le vote Front national. Il s'agirait à la fois d'une "réticence à avouer" et d'un effet de "souvenir". Dans le reste de la discussion, dès qu'il y a des questions sur cette variable de redressement, il s'agit de "sous-souvenir" ou de "sur-souvenir", ce qui est assez cocace. Mais ce que les sondeurs qualifient de souvenir variable pourrait très bien être… un échantillon non représentatif. Si les personnes qui ont voté pour Jean-Marie Le Pen, Marine Le Pen ou Jean-Luc Mélenchon sont sous-représentées dans le panel initial, il est logique que leur "souvenir" apparaisse plus bas qu’il ne devrait. Ce n’est pas qu’ils ont oublié. C’est peut-être juste qu’ils ne sont pas là.

Agrandissement : Illustration 4

Ce glissement sémantique est révélateur. En parlant d’erreur de mémoire, on reporte la faute sur l’électeur ("il ne se souvient pas"), au lieu de l’assumer comme un défaut du dispositif d’enquête ("nous n’avons pas assez bien capté cette population"). C’est une manière élégante de camoufler une faiblesse méthodologique, et surtout de préserver l’illusion d’un échantillon initial représentatif, qu’on pourrait ensuite simplement "redresser".
En fin de compte, le redressement n'est pas un cache-misère. C'est un révélateur. Il permet d'améliorer la qualité d'une estimation, de réduire le biais tout en diminuer la variance, mais aussi de mettre en évidence les limites de l'échantillon. Un sondage qui a besoin de beaucoup être redressé est un sondage qui pose question. Plutôt que de se demander si redresser, c'est tricher, on devrait peut-être se demander pourquoi il faut redresser autant.
Post-scriptum
La commission d'enquête se pose la question de savoir s'il faudrait publier les résultats "bruts", c'est-à-dire avant redressement. L'idée peut paraître vertueuse au nom de la transparence, mais elle pose problème. Ces données non redressées sont, par construction, biaisées : elles ne représentent pas fidèlement la population, et leur diffusion pourrait entretenir la confusion plutôt que l'éclairer.
La transparence serait mieux servie, selon moi, par la mise à disposition des poids individuels, avant et après redressement, au moins pour l'instance chargée d'évaluer la qualité du sondage, voire pour les chercheur·ses ou citoyen·nes qui en feraient la demande. Mais publier deux jeux de résultats, dont l'un est volontairement erroné, reviendrait surtout à brouiller le message. Et à affaiblir, à tort ou à raison, la confiance dans un outil déjà fragile.

Agrandissement : Illustration 5
