



Lorsqu’on confronte les sondages d’intention de vote au scrutin, la critique revient inlassablement : “les sondages se sont trompés”. Tel·le candidat·e aurait été surévalué·e, ou sous-estimé·e, et les instituts tentent ensuite d’expliquer l’écart. J’en avais parlé ici, en recensant les principales justifications avancées. La commission d'enquête sur les sondages aussi, d'ailleurs, j'en parle ici.
Aujourd’hui, je voudrais retourner la perspective. Et si, pour une fois, ce n’étaient pas les sondages qui avaient tort… mais le vote lui-même ?
Derrière cette question provoquante bien sûr se cache une réflexion sur la représentativité, le biais d’abstention, et la manière dont on accepte, ou non, de redresser des données pour qu’elles reflètent fidèlement une population.
Rappel, c'est quoi un redressement ?
Il y a quelques semaines, j’évoquais la question du redressement des sondages. Il s'agit d'une opération qui consiste à ajuster les résultats pour que l’échantillon colle mieux aux caractéristiques connues de la population. Tous les instituts y ont recours, et détaillent, dans leurs notices méthodologiques, les variables utilisées pour cela. Il s’agit le plus souvent de l’âge, du sexe, de la catégorie socioprofessionnelle, parfois ventilés par région.
On peut, bien sûr, discuter les techniques employées (je l’ai fait ici), mais l’objectif reste globalement le même : pour les statisticien·nes, il s’agit de réduire la variance des estimations ; pour les acteurs politiques ou médiatiques, de se rapprocher d’un portrait fidèle de la population, ce fameux "échantillon représentatif".
Et l’intention me paraît tout à fait louable. Reste à savoir sur quelles variables on choisit de s’appuyer. Est-ce la parité hommes/femmes qu’il faut garantir ? L’âge est-il un bon prédicteur du vote ? Les classes de revenus ne devraient-elles pas peser davantage ? Autant de choix méthodologiques mais aussi forcément politiques.
Redresser un vote ??
Mais alors, si l’on accepte sans sourciller le redressement des sondages (1), pourquoi ne pas appliquer ce même principe… au vote lui-même ? Car, entre les personnes non inscrites et celles qui s’abstiennent, le vote tel qu’il est pratiqué n’est rien d’autre qu’un sous-échantillon de la population totale. Une minorité décide pour le tout et cette décision, l’élection d’un·e représentant·e, est pourtant censée engager l’ensemble.
D’un point de vue strictement statistique, il serait donc logique de redresser les résultats électoraux, comme on le fait pour un sondage. Cela permettrait d’approcher plus fidèlement la volonté générale, celle qu’on aurait obtenue si tout le monde avait voté. Oui, je tente dans ce billet le parallèle : voter ou répondre à un sondage, c’est dans les deux cas participer à un dispositif qui cherche à refléter l’avis d’une population entière à partir d’un échantillon partiel.
Dans un sondage, on cherche à connaître l’avis d’une population entière, mais on ne questionne qu’un échantillon. Pourquoi ? Parce qu’interroger tout le monde serait trop coûteux, trop long, voire tout simplement impossible. Heureusement, la théorie statistique nous apprend qu’un bon échantillon (bien conçu, bien redressé) peut fournir une estimation fiable de l’ensemble.
Dans le cas du vote, c’est presque l’inverse : on offre à toute la population la possibilité de s’exprimer. Le coût est immense, mais le dispositif est censé garantir une pleine participation. Pourtant, une partie importante ne répond pas : c’est l’abstention. On se retrouve donc, comme dans un sondage, avec un échantillon partiel. Sauf qu’ici, il n’a pas été tiré au sort : il résulte d’un mécanisme de non-réponse biaisé.
Et quand on calcule les résultats à partir de ce sous-ensemble, on n’obtient pas une estimation fidèle de l’ensemble de la population : on obtient une mesure biaisée. Non pas à cause d’un défaut de tirage, mais à cause de la non-réponse, comme dans un sondage.
Bien sûr, si l’abstention était répartie de manière parfaitement aléatoire dans la population, il n’y aurait pas de problème : le résultat serait seulement un peu moins précis, car basé sur moins de répondant·es. Autrement dit, on augmenterait la variance, mais sans introduire de biais. C’est d’ailleurs ce que suppose implicitement notre système électoral : chaque votant·e compte pour un, on fait la somme, et on élit. Les abstentionnistes sont écarté·es du calcul, alors que le résultat final “les Français·es ont choisi X” les concerne tout autant.
La faute aux absentionnistes ?
Alors, sur qui fait-on reposer la responsabilité de ce biais électoral ? Sur les abstentionnistes, évidemment. Iels avaient la possibilité de s’exprimer, mais ont choisi de ne pas le faire. Le système ne les considère donc plus. On ne parle même pas de résultat biaisé : on parle d’un résultat “légitime”, qui ne correspond simplement pas aux attentes de celles et ceux qui se sont abstenus.
Maintenant, imaginez qu’on applique la même logique dans les sondages réalisés par l’Insee en France, ou par Statbel en Belgique. On publierait, sans correction aucune, des chiffres bruts issus des seules personnes ayant répondu :
“Chute spectaculaire de la pauvreté !”
“Le chômage s’effondre dans toutes les régions !”
“L’usage d’Internet dépasse les 99 % !”
Et pour cause : les plus précaires, les plus isolé·es, les moins connecté·es sont aussi celles et ceux qui répondent le moins aux enquêtes. Ce biais est bien connu, documenté, corrigé. Il est même considéré comme une obligation professionnelle : redresser, c’est garantir une certaine fidélité à la réalité sociale. Les instituts d’opinion suivent la même règle : sans redressement, leurs résultats n’auraient aucune valeur prédictive ni descriptive. Alors pourquoi fait-on preuve d’autant d’exigence méthodologique ici et pas lorsqu’il s’agit d’un vote ?
On me rétorquera : “Mais enfin, tout le monde peut voter ! Ce n’est pas comparable aux sondages, où seul·es quelques-un·es sont contacté·es.”
Cet argument semble de bon sens, mais il ne tient pas… du moins si l’on parle de sondages probabilistes, ceux où les personnes sont tirées aléatoirement dans l’ensemble de la population. Dans ce cadre, chaque individu a (en théorie) la même chance d’être interrogé. Et si tout le monde répondait, le redressement serait inutile : l’échantillon serait déjà parfaitement représentatif.
Mais ce n’est jamais le cas. Certains refusent de répondre, ne sont pas disponibles, ne se sentent pas concernés. C’est la non-réponse qui crée le déséquilibre, et qui rend le redressement nécessaire, non pas l'échantillonnage. Exactement comme dans le cas du vote. Tout le monde peut voter, mais tout le monde ne le fait pas. Et comme cette abstention n’est pas aléatoire, elle biaise le résultat. C’est donc elle, et non le principe du suffrage universel, qui rend légitime l’idée d’un redressement électoral.
Passons au concret : comment redresser un vote ?
Cela signifie faire un choix. Choisir de faire en sorte que la répartition des votant·es reflète mieux celle de l’ensemble de la population, selon certaines caractéristiques jugées pertinentes : l’âge, le sexe, le niveau de diplôme, la catégorie socioprofessionnelle…
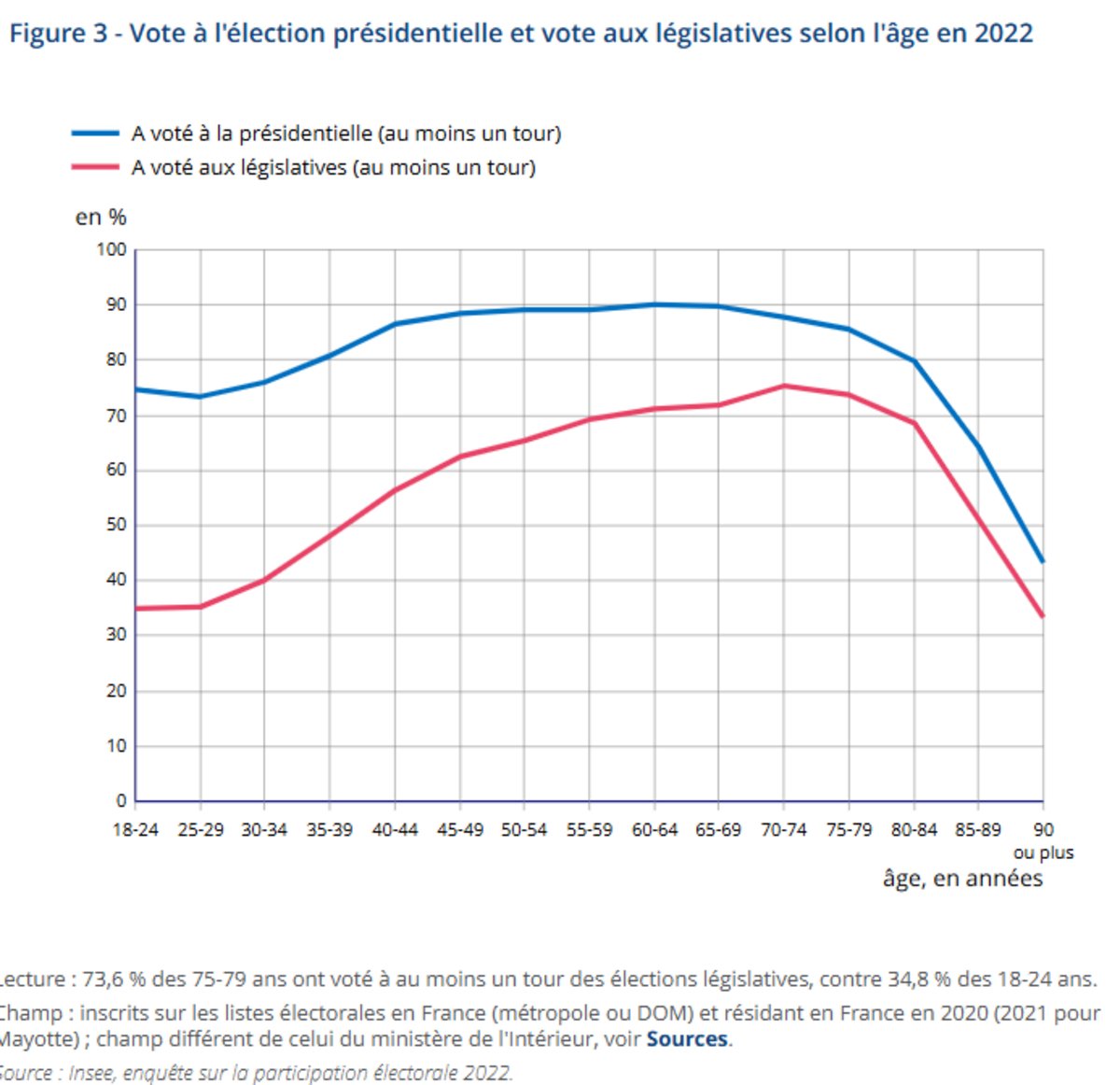
Agrandissement : Illustration 1
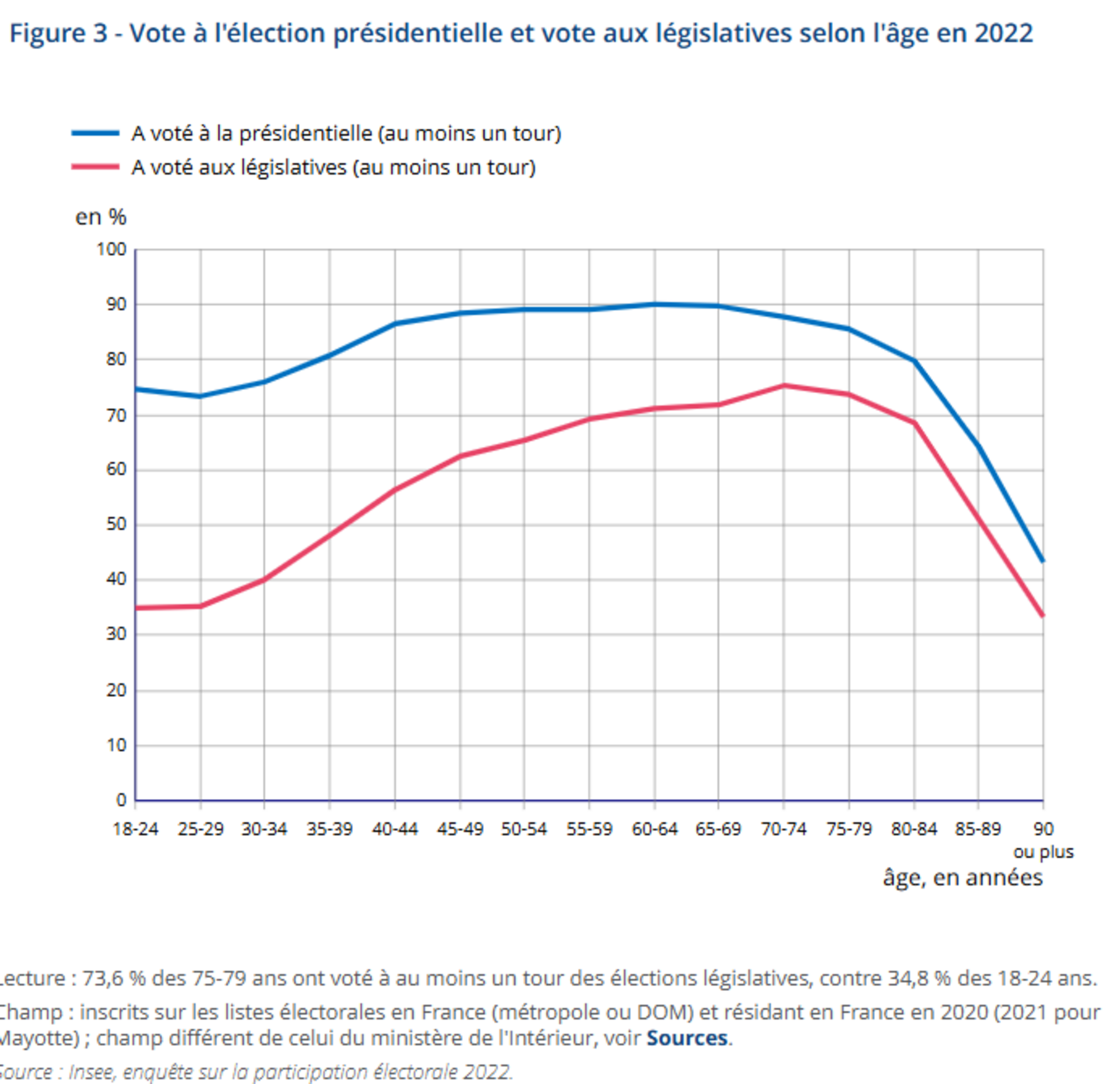
Par exemple : si les jeunes votent peu, on peut décider que leur poids électoral sera revalorisé, pour que leur part dans le résultat final corresponde à leur part dans la population. Ce n’est donc plus uniquement la voix des individus présents dans l’urne qui compte, mais aussi celle de leur “groupe d’appartenance”.
Dit autrement : si tu ne votes pas, tu ne laisses pas le champ libre à ceux qui se sont déplacés, tu “transmets” symboliquement ta voix à la tendance majoritaire de ta catégorie. Est-ce mieux ? Est-ce pire ? C’est un débat politique, mais ce n’est pas une aberration technique : c’est déjà ce que l’on fait dans bien d’autres situations de non-réponse, notamment dans les sondages ou les enquêtes sociales.
Reste à définir quelles variables utiliser pour redresser. En science politique, le niveau de revenu est souvent cité comme un bon prédicteur du comportement électoral. Si l’on voulait minimiser le biais, ce serait une dimension à prendre en compte, peut-être même plus que l’âge ou le sexe. Cela dit, de récentes analyses montrent que le vote des jeunes hommes semble s'écarter sensiblement de celui des jeunes femmes.
Et l'anonymat dans tout cela ?
Mais comment appliquer concrètement ce redressement, sans porter atteinte au secret du vote ? Dans les sondages, c’est relativement simple : les répondant·es peuvent déclarer certaines caractéristiques personnelles (âge, sexe, profession…), et les instituts choisissent ensuite les variables de redressement les plus pertinentes. Pour un vote, c’est évidemment plus délicat. Le scrutin doit rester strictement anonyme. Or, pour redresser, il faut pouvoir rattacher chaque voix exprimée à certaines caractéristiques, sans jamais identifier l’électeur ou l’électrice.
Est-ce infaisable pour autant ? Pas nécessairement. On pourrait imaginer des dispositifs où seules les variables de redressement, et non l’identité, sont connues au moment du vote. Par exemple, lors de l’émargement, une information comme l’année de naissance, extraite automatiquement du registre national en Belgique, pourrait permettre de placer le vote dans la bonne "strate" démographique, sans que le contenu du vote soit jamais relié à l’individu. Ce serait une forme de pondération intégrée au moment du dépouillement, et non après coup.
Un autre scénario (moins élégant, mais plus visuel) consisterait à distribuer des enveloppes pré-codées selon des catégories connues (âge, sexe, revenu déclaré) sans que cela ne permette d’identifier la personne. Le bulletin resterait secret, mais serait ensuite agrégé dans la bonne catégorie.
Rien de tout cela n’est anodin, ni techniquement simple. Mais ce n’est pas plus invasif que certaines pratiques déjà à l’œuvre dans le vote électronique en Belgique notamment, où le registre national est déjà mobilisé pour garantir l’unicité du vote. La vraie difficulté n’est pas tant technique que juridique et symbolique : à quel point est-on prêt à introduire des métadonnées dans un processus censé être neutre ?
Une petite illustration pour rendre cela plus concret
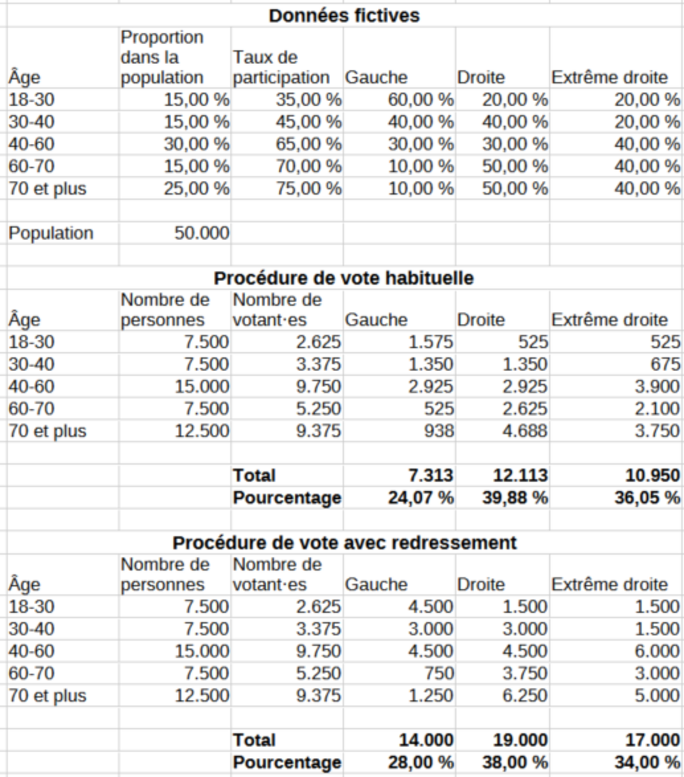
Imaginons une population divisée en cinq classes d’âge, et trois grandes orientations politiques : gauche, droite, extrême droite. Les chiffres sont fictifs, mais cet exercice pourrait tout à fait être mené avec des données réelles. Dans ce scénario, sans redressement, c’est-à-dire en ne tenant compte que des suffrages exprimés — la droite recueille 39,88 % des voix. Une fois les résultats redressés pour correspondre à la structure par âge de l’ensemble de la population en âge de voter, la droite tombe à 38 %. Ce glissement sémantique est important : on passe d’un résultat sur les votant·es à une estimation sur l’ensemble des citoyen·nes en âge de voter. C’est exactement la même logique que dans les sondages.
Dans cet exemple, la gauche progresse fortement (de 24 % à 28 %), car elle est davantage soutenue par les jeunes, lesquels sont aussi les plus abstentionnistes. Un vote redressé leur rend donc un poids qu’ils n’ont pas exprimé dans l’urne. Dit autrement : un vote “jeune” pèserait plus, pour compenser l’abstention dans cette classe d’âge.
Pour autant, on ne bouleverse pas l’ordre des tendances politiques. La droite reste en tête, l’extrême droite en deuxième position, la gauche troisième. Et c’est sans doute ce qui se passerait dans la réalité : le redressement ne crée pas de révolution électorale. Mais ce n’est pas une raison pour l’ignorer. D’ailleurs, j’avais testé cette logique à l’époque de l’élection présidentielle de 2022. Même avec un redressement fondé sur des classes d'âge, cela n’avait pas permis à Jean-Luc Mélenchon d'atteindre le second tour. Comme dans les sondages, le redressement améliore la représentation mais il ne réécrit pas l’histoire.
Pourquoi tout cela ?
Je ne cherche pas ici à proposer une réforme du système électoral. Si réforme il devait y avoir, elle devrait sans doute être plus profonde, plus structurelle. Ce n’est clairement pas mon propos ici. Ce billet est avant tout une invitation à prendre du recul. À s’interroger sur ce que l’on considère comme un “résultat” légitime lorsqu’il s’agit d’exprimer la volonté d’un collectif. À remettre en question, aussi, l’idée selon laquelle le vote, parce qu’universel en droit, serait nécessairement représentatif en fait. Et que cela se rapproche du domaine que je maîtrise un peu mieux, à savoir les sondages.
Car au fond, un vote, même à l’échelle d’une population entière, n’est peut-être rien d’autre qu’une version exhaustive mais incomplète du “1000 personnes pensent que…” qui à donné son titre à ce blog. Une mesure, elle aussi, conditionnée par des choix techniques et des règles qu’on ne questionne plus. Réfléchir aux biais du vote, c’est aussi mieux comprendre ceux des sondages. Et inversement. Dans les deux cas, on fabrique une vérité collective à partir d’expressions individuelles, et ici surtout de silences, qu’il faut toujours interroger.
(1) Antoine Léaument, lui, ne l’accepte pas sans sourciller, comme il l’a exprimé lors de la dernière commission d’enquête sur les sondages, j'en parle ici.